Python требует ясной структуры и читаемости кода. Основной принцип – следование PEP 8: отступы в 4 пробела, ограничение длины строки 79 символами, использование snake_case для переменных и функций, PascalCase для классов. Эти правила уменьшают вероятность ошибок при совместной работе и облегчают поддержку проектов.
Инициализация переменных должна быть информативной: имена count_items или user_profile сразу отражают назначение. Избегайте сокращений, которые не общеприняты, и старайтесь минимизировать глобальные переменные, перемещая их в функции или классы.
Для управления зависимостями используйте виртуальные окружения: venv или pipenv. Каждый проект должен иметь отдельное окружение с конкретными версиями библиотек, чтобы избежать конфликтов и сохранить воспроизводимость кода на разных машинах.
Модули и пакеты структурируйте по функционалу. Файлы должны быть небольшими – до 300 строк, чтобы поддерживать высокую читаемость. Встроенные комментарии и docstring в функциях описывают параметры и возвращаемые значения, позволяя использовать автоматическую генерацию документации с Sphinx.
Исключения обрабатываются через try/except блоки с конкретными типами ошибок. Не используйте общий except:, чтобы не скрывать ошибки. Логирование через модуль logging позволяет отслеживать выполнение кода без прерывания работы программы.
Согласованное именование переменных и функций
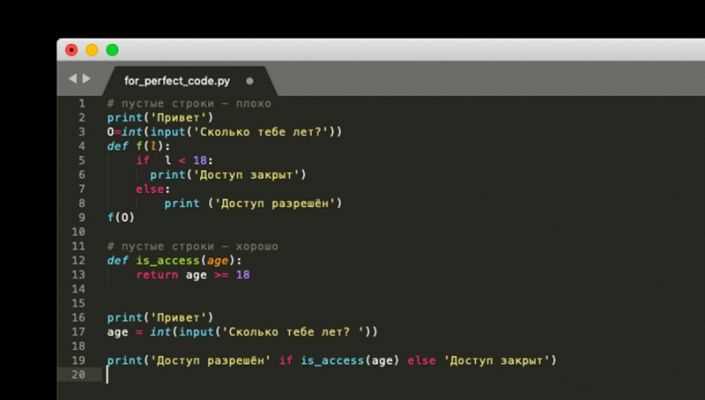
Согласованное именование переменных и функций повышает читаемость и поддерживаемость кода. В Python принято использовать стиль snake_case для переменных и функций и PascalCase для классов. Имена должны отражать назначение объекта, избегая аббревиатур, неочевидных сокращений и односимвольных обозначений, кроме итераторов.
Для переменных:
| Тип | Пример | Описание |
|---|---|---|
| Счетчик или индекс | index, i | Краткое имя допустимо для локальных циклов |
| Логическая переменная | is_active, has_error | Начало с глагола или вспомогательного слова для булевых значений |
| Списки и коллекции | user_list, orders_set | Множественное число для списков, суффиксы _set или _dict для других коллекций |
| Объекты и сущности | user_profile, payment_info | Четкое описание содержимого переменной |
Для функций:
| Тип функции | Пример | Описание |
|---|---|---|
| Действие над объектом | calculate_total(), send_email() | Имя начинается с глагола, отражает выполняемое действие |
| Проверка состояния | is_valid(), has_permission() | Возвращает булево значение, начинается с вспомогательного глагола |
| Получение данных | get_user_info(), fetch_orders() | Описывает источник и тип возвращаемых данных |
| Преобразование данных | format_date(), normalize_text() | Четко указывает на изменение объекта или структуры |
Общие рекомендации:
- Не использовать смешанный стиль именования в рамках одного проекта.
- Имена длиной 3–20 символов обеспечивают баланс между понятностью и компактностью.
- Избегать однобуквенных имен вне локальных циклов.
- Документировать нестандартные сокращения в коде.
- Применять единый подход к приставкам и суффиксам для булевых переменных, коллекций и функций.
Соблюдение этих правил снижает вероятность ошибок и ускоряет понимание кода другими разработчиками.
Использование типов данных для предотвращения ошибок
Типы данных в Python определяют набор допустимых операций над значениями. Ошибки часто возникают при некорректном применении этих операций, например, попытка сложить строку и число вызывает TypeError. Чтобы избежать таких ситуаций, рекомендуется явно проверять типы входных данных перед обработкой.
Использование аннотаций типов позволяет IDE и статическим анализаторам, таким как mypy, выявлять несоответствия до выполнения программы. Например, указание функции: def add(a: int, b: int) -> int: предотвращает случайную передачу строк или списков вместо чисел.
Коллекции Python, такие как списки, словари и множества, выигрывают от указания типов элементов через модуль typing. Пример: users: list[str] = [] помогает отслеживать добавление некорректных значений, уменьшая вероятность ошибок при обработке данных.
Для сложных структур данных рекомендуется использовать TypedDict или dataclass, что обеспечивает контроль типов на уровне ключей и атрибутов. Это предотвращает ошибки доступа к несуществующим полям и неправильное присвоение значений.
При работе с внешними данными, например из JSON или API, полезно применять проверку типов через pydantic или кастомные валидаторы. Они гарантируют соответствие данных ожидаемым типам и структурам, снижая риск неожиданных исключений в рантайме.
Использование типов данных в сочетании с проверками и инструментами статического анализа повышает читаемость кода и минимизирует ошибки, которые иначе выявляются только во время выполнения. Планомерное внедрение аннотаций и проверок делает код устойчивым к изменениям и упрощает отладку.
Структурирование кода с помощью функций и классов

Функции в Python позволяют изолировать повторяющийся код и упрощают его тестирование. Оптимальная длина функции – 15–25 строк, каждая функция должна выполнять одну конкретную задачу. Аргументы функции следует ограничивать 3–5 параметрами; при необходимости использовать словари или объекты для передачи данных.
Именование функций должно отражать действие: глаголы в нижнем регистре с подчеркиваниями, например calculate_sum() или fetch_data(). Возвращаемые значения желательно явно указывать с помощью return, избегая побочных эффектов внутри функции.
Классы применяются для объединения данных и поведения, связанных с одной сущностью. Каждый класс должен представлять логическую единицу, а методы класса – операции над его состоянием. Именование классов следует вести в стиле CamelCase, например UserProfile.
Рекомендуется использовать конструктор __init__ для обязательных атрибутов и приватные методы или свойства для внутренних операций. Методы класса должны быть короткими и независимыми друг от друга, при этом можно выделять вспомогательные функции вне класса для повышения читаемости.
Для модульности кода стоит разделять функции и классы по файлам: логически связанные классы объединять в модули, а модули – в пакеты. При этом следует избегать циклических импортов и держать зависимости минимальными. Документирование функций и методов через docstring с указанием типов аргументов и возвращаемых значений улучшает поддержку и автоматическую генерацию документации.
Использование функций и классов вместе позволяет реализовать принципы SOLID: разделение ответственности, открытость для расширений и закрытость для модификаций. Это упрощает рефакторинг, тестирование и повторное использование кода в разных проектах.
Обработка исключений и контроль ошибок
В Python для управления ошибками используется конструкция try-except. Она позволяет изолировать потенциально опасный код и предотвращает аварийное завершение программы.
Рекомендуется ловить конкретные исключения, а не использовать общий except без указания типа ошибки. Например, при работе с файлами используйте except FileNotFoundError: вместо универсального except:. Это повышает читаемость и облегчает отладку.
Можно добавлять блок else после except, чтобы код выполнялся только при отсутствии ошибок. Такой подход упрощает понимание логики и снижает риск скрытых ошибок.
Для окончательной обработки ресурсов применяйте блок finally. Он гарантирует выполнение кода независимо от того, возникло исключение или нет, что критично при работе с файлами, сетевыми соединениями и базами данных.
Для сложных операций полезно создавать собственные исключения, наследуя Exception. Это помогает разделять ошибки по типу и упрощает обработку на более высоком уровне программы.
Использование raise позволяет повторно генерировать исключение или создавать цепочку ошибок, сохраняя исходный контекст. Это важно для логирования и анализа причин сбоя.
Логирование ошибок с помощью модуля logging предпочтительнее простого print, так как обеспечивает сохранение информации о времени, уровне ошибки и источнике.
При проектировании модулей рекомендуется документировать возможные исключения через docstring и аннотации, чтобы пользователи кода знали, какие ошибки могут возникнуть и как их безопасно обработать.
Комментарии и документация для поддерживаемого кода
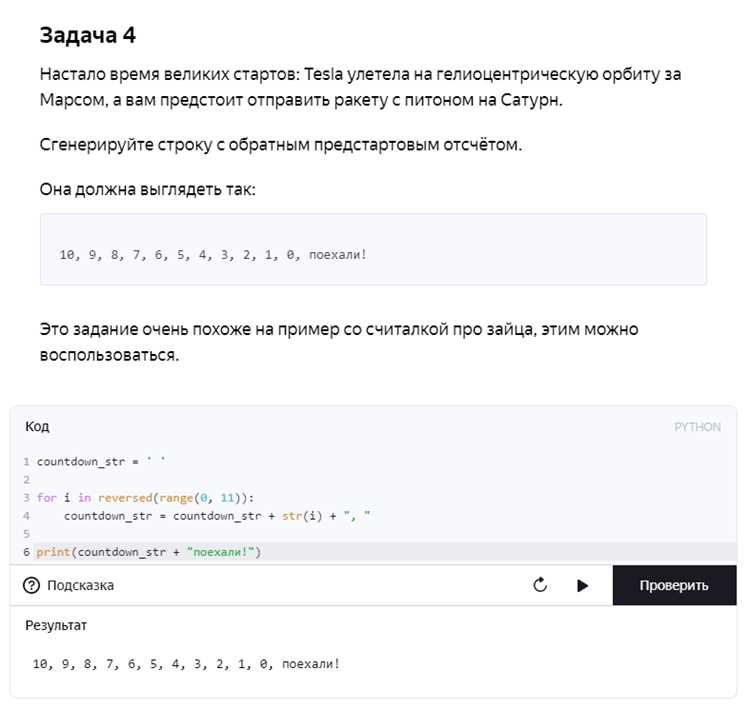
Комментарии в Python должны объяснять *почему* выполняется та или иная логика, а не *что* делает код. Избыточные комментарии, повторяющие синтаксис, снижают читаемость и отвлекают. Используйте однострочные комментарии с символом # для локальных пояснений и многострочные строки """... для описания функций и классов.
Докстринги должны следовать формату PEP 257: первая строка – краткое описание, затем пустая строка и подробное объяснение при необходимости. Пример структуры функции:
def calculate_area(radius):
"""Вычисляет площадь круга по радиусу.
radius: float – радиус круга
return: float – площадь круга
"""
return 3.14159 * radius ** 2
Для модулей создавайте отдельный блок документации в начале файла с описанием назначения модуля, основных функций и зависимостей. Используйте ясные имена параметров и типов, чтобы уменьшить необходимость в дополнительных пояснениях.
Инструменты автоматической генерации документации, такие как Sphinx или pdoc, требуют корректных и полных докстрингов. Следовательно, четко структурированные и стандартизированные комментарии повышают эффективность поддержки и упрощают интеграцию в системы CI/CD.
Комментарии должны обновляться одновременно с изменением кода. Старые или неверные комментарии опаснее отсутствия, так как они вводят в заблуждение. Следите за согласованностью стиля с PEP 8: используйте заглавные буквы в начале, точки в конце предложений и минимизируйте аббревиатуры без пояснений.
Для сложных алгоритмов допускается добавление блоков комментариев с шагами вычислений, примерами входных и выходных данных и ссылками на документацию или статьи, которые объясняют используемый метод. Это облегчает повторное использование и тестирование кода.
Стандарты форматирования и отступов в Python

Python использует отступы для определения блоков кода вместо фигурных скобок. Рекомендуемый размер отступа – 4 пробела. Использование табуляции или смешанных отступов строго запрещено, так как это вызывает синтаксические ошибки.
Основные правила форматирования:
- Максимальная длина строки – 79 символов для кода и 72 для строк документации.
- Импорт модулей оформляется отдельными строками и разделяется на стандартные библиотеки, сторонние пакеты и локальные модули.
- Между функциями и классами необходимо оставлять две пустые строки, внутри методов – одну.
- Использование пробелов вокруг операторов и после запятых должно быть единообразным:
a = b + c,func(x, y). - Скобки в выражениях рекомендуется размещать без лишних пробелов:
func(a[0], b[1]),if (x == y):. - Строковые литералы предпочтительно заключать в одинарные кавычки, но внутри документации допускаются тройные кавычки для многострочного текста.
Отдельные рекомендации по отступам:
- Вложенные блоки должны увеличиваться ровно на 4 пробела. Например, тело функции, условного оператора или цикла:
- Для длинных выражений допускается перенос с дополнительным отступом в 4 пробела от предыдущей строки:
- Отступы внутри списков, словарей или кортежей должны быть согласованы с открывающей скобкой:
- Блоки try/except/finally и with должны выравниваться строго по отступам вложенности.
- Комментарии располагаются на отдельной строке или после кода с двумя пробелами перед символом
#.
def func():
if condition:
do_something()result = some_function(arg1, arg2,
arg3, arg4)my_list = [
1,
2,
3,
]Соблюдение этих стандартов повышает читаемость, упрощает поддержку кода и снижает вероятность синтаксических ошибок, особенно в командной разработке.
Вопрос-ответ:
Какие основные принципы нужно учитывать при оформлении кода на Python?
При оформлении кода на Python стоит ориентироваться на читаемость и ясность. Это означает использование понятных имен переменных, функций и классов, соблюдение единообразного отступа, правильное разделение логических блоков и аккуратное использование комментариев. Также следует придерживаться общепринятого стиля PEP 8, который регламентирует длину строк, пробелы вокруг операторов и оформление функций. Такой подход помогает другим разработчикам быстрее понимать и поддерживать код.
Как структурировать проект на Python, чтобы код было легко поддерживать?
Структурирование проекта должно учитывать его размер и сложность. Для небольших скриптов можно ограничиться отдельными модулями, тогда как для больших проектов рекомендуется создавать пакеты, выделяя модули по функциональному назначению. Разделение кода на отдельные файлы с логически связанными функциями, использование конфигурационных файлов и папок для ресурсов упрощает масштабирование проекта и ускоряет поиск ошибок.
Почему важно тестировать Python-код и какие подходы существуют?
Тестирование позволяет убедиться, что код выполняет поставленные задачи корректно и стабильно. Существуют разные подходы: модульное тестирование проверяет отдельные функции и методы, интеграционное — работу нескольких компонентов вместе, а функциональное — выполнение программы в целом. В Python часто используют библиотеки unittest или pytest. Написание тестов помогает выявить ошибки на ранней стадии и облегчает внесение изменений без риска нарушить логику работы.
Как правильно документировать функции и классы в Python?
Документирование функций и классов упрощает понимание их назначения другими разработчиками. Для этого обычно используют строковые литералы (docstrings), которые располагаются сразу после объявления функции или класса. В docstring описывают, что делает объект, какие параметры принимает, что возвращает и какие исключения может вызвать. Кроме того, рекомендуется писать примеры использования. Такой подход делает код понятным и облегчает автоматическую генерацию документации с помощью инструментов вроде Sphinx.