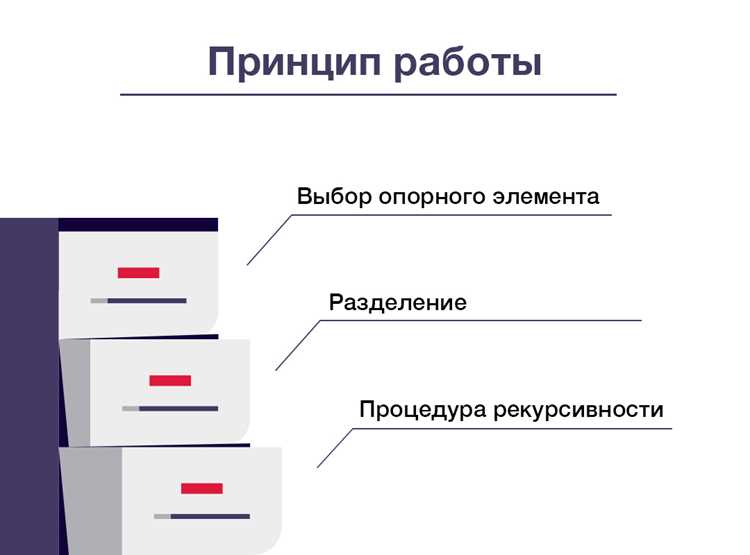
Быстрая сортировка (Quicksort) – это алгоритм, основанный на принципе «разделяй и властвуй». В Python его реализация часто используется из-за своей эффективности при сортировке больших данных. Основной принцип алгоритма заключается в том, чтобы выбрать элемент (опорный) и разделить массив на две части: одну с элементами меньше опорного, другую – с элементами больше. Этот процесс повторяется рекурсивно для каждой из частей.
Алгоритм быстрой сортировки начинается с выбора опорного элемента из массива. Обычно выбирается элемент в середине массива, однако возможны и другие стратегии. Разделение происходит таким образом, что элементы слева от опорного меньше его, а справа – больше. Важно, что для каждого раздела выполняется тот же процесс, пока не будут достигнуты подмассивы с длиной, равной 1 или 0, что является условием завершения рекурсии.
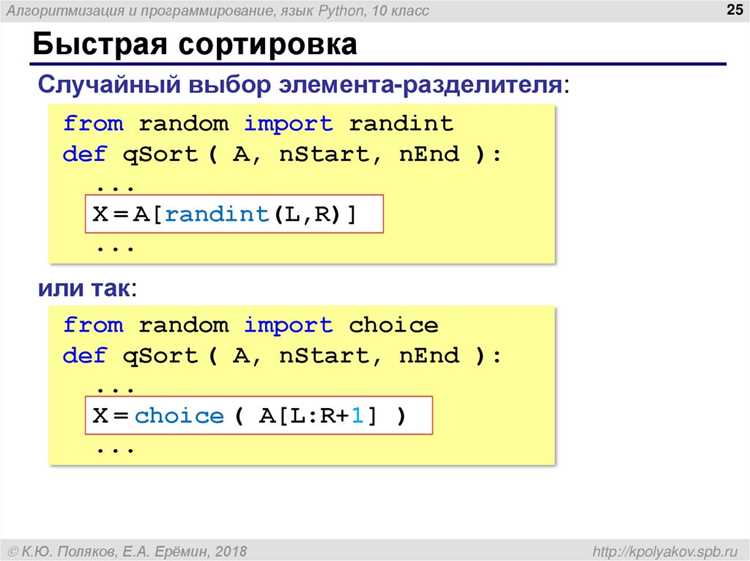
Реализация быстрой сортировки в Python часто использует метод сортировки с разделением по индексу, что позволяет эффективно обрабатывать большие массивы. Для улучшения производительности стоит использовать случайный выбор опорного элемента, что уменьшает вероятность появления худших случаев (O(n^2)) и позволяет работать в среднем за O(n log n).
Использование быстрой сортировки в Python требует учета особенностей языка. Например, для работы с большими массивами стоит обратить внимание на ограничения глубины рекурсии, которые могут быть увеличены с помощью функции sys.setrecursionlimit(), если это необходимо. Однако для маленьких массивов или массивов с почти отсортированными данными, более подходящей может быть сортировка методом слияния или сортировка вставками.
Выбор опорного элемента для разных списков

Выбор опорного элемента (пивота) играет ключевую роль в эффективности быстрой сортировки. Правильный выбор может значительно повлиять на производительность алгоритма, особенно для уже отсортированных или почти отсортированных списков.
Для произвольных списков, где элементы распределены случайным образом, оптимальным подходом является выбор опорного элемента, например, медианы случайных элементов. Использование медианы позволяет избежать крайних ситуаций, таких как рекурсивный вызов для одномерных списков, что случается при выборе первого или последнего элемента как пивота.
Для отсортированных или почти отсортированных списков наибольшая проблема возникает при выборе первого или последнего элемента как опорного. В этих случаях алгоритм может деградировать до квадратичной сложности O(n^2). Чтобы предотвратить это, рекомендуется использовать медиану трёх элементов: первого, среднего и последнего. Это минимизирует риск худших временных затрат, так как медиана трёх элементов обычно даёт более сбалансированные разделения.
При работе с большими объёмами данных или при повторяющихся элементах эффективнее всего будет выбирать опорный элемент случайным образом. Такой подход гарантирует, что даже в случае частых одинаковых значений, производительность алгоритма не будет сильно страдать.
Если список уже отсортирован, использование медианы трёх элементов или случайного выбора будет лучшим решением для предотвращения ухудшения производительности. В большинстве реальных сценариев такой выбор опорного элемента обеспечит более высокую скорость сортировки.
Разделение массива на подмассивы с помощью алгоритма Lomuto и Hoare
Алгоритм Lomuto
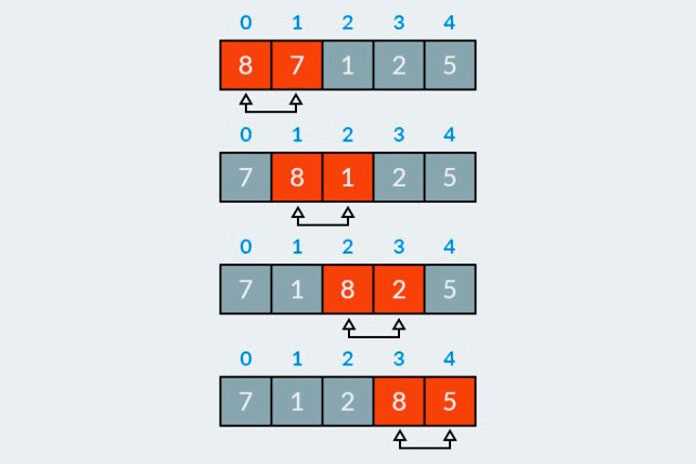
В алгоритме Lomuto опорный элемент выбирается обычно как последний элемент массива или подмассива. Процесс разбиения состоит в том, чтобы переместить все элементы меньшие или равные опорному элементу влево, а большие – вправо. Алгоритм выполняет следующие шаги:
- Выбирается опорный элемент (в большинстве случаев – последний элемент).
- Производится перестановка элементов: элементы, меньшие или равные опорному, перемещаются влево, остальные – вправо.
- Опорный элемент встает на свое окончательное место, таким образом, массив разделяется на два подмассива.
Основное преимущество алгоритма Lomuto – его простота. Однако, его недостаток – неэффективность на больших данных из-за большого числа лишних обменов и сравнений.
Алгоритм Hoare
Алгоритм Hoare является более оптимизированной версией разбиения массива. В отличие от Lomuto, где опорный элемент всегда перемещается в конец, в алгоритме Hoare выбор опорного элемента происходит изначально, а разбиение выполняется с двух сторон массива. Алгоритм работает следующим образом:
- Опорным элементом выбирается элемент, находящийся в середине массива.
- Используются два указателя: один движется слева, другой – справа.
- Указатель слева ищет элемент, который больше или равен опорному, а указатель справа – элемент, который меньше опорного.
- После нахождения таких элементов они меняются местами, и процесс продолжается, пока указатели не пересекутся.
- Массив разделяется на два подмассива относительно опорного элемента.
Алгоритм Hoare эффективнее, так как обменов и сравнений в нем меньше. Это делает его более предпочтительным для сортировки больших массивов.
Сравнение алгоритмов
- Производительность: Hoare обычно работает быстрее, так как количество обменов и сравнений в нем меньше.
- Память: Оба алгоритма работают на месте, то есть не требуют дополнительной памяти для создания новых массивов.
- Реализация: Алгоритм Lomuto проще в реализации, но менее эффективен на больших данных.
Таким образом, выбор между алгоритмами зависит от требований к скорости и сложности реализации. В случае сортировки небольших массивов можно использовать алгоритм Lomuto, а для больших данных предпочтительнее выбрать алгоритм Hoare.
Рекурсивная обработка подмассивов в Python
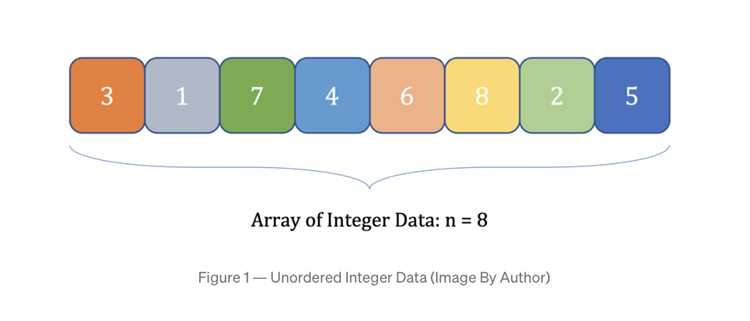
Основная идея заключается в том, что рекурсивная функция вызывает себя для обработки подмассивов, образующихся после разделения. Рекурсия начинается с полного массива, затем с каждым шагом обрабатываются его части. Важно, что каждый вызов функции работает только с частью массива, что позволяет избежать повторной сортировки уже отсортированных участков.
Пример рекурсивной функции для быстрой сортировки:
def quicksort(arr): if len(arr) <= 1: return arr pivot = arr[0] less = [x for x in arr[1:] if x <= pivot] greater = [x for x in arr[1:] if x > pivot] return quicksort(less) + [pivot] + quicksort(greater)
В этом примере рекурсия заканчивается, когда длина подмассива становится меньше или равна единице, то есть подмассивы уже отсортированы.
Важно учитывать, что на каждом уровне рекурсии происходит разделение на два подмассива, что приводит к экспоненциальному росту вызовов функции. Это требует внимания к глубине рекурсии, особенно при сортировке больших массивов. Для предотвращения переполнения стека можно использовать итеративные методы или ограничения на глубину рекурсии в Python.
Рекомендация: для улучшения производительности и предотвращения излишней рекурсии стоит выбирать опорный элемент с учетом статистики массива, например, медиану трех элементов.
Оптимизация рекурсии с учётом глубины вызовов

При реализации алгоритма быстрой сортировки на Python важно учитывать глубину рекурсивных вызовов, так как слишком глубокая рекурсия может привести к переполнению стека. Для минимизации этого риска используется несколько подходов, направленных на оптимизацию рекурсивной части алгоритма.
Первый метод заключается в ограничении максимальной глубины рекурсии. Для этого можно применить параметр sys.setrecursionlimit(), который позволяет установить предел глубины рекурсии. Однако этот метод подходит не для всех случаев, так как он может повлиять на другие части программы, требующие более глубокой рекурсии.
Второй подход включает использование итеративной версии быстрой сортировки. Суть метода заключается в замене рекурсии на стек для хранения индексов. Вместо того чтобы вызывать функцию для каждого подмассива, можно явно управлять стеком, что позволяет избежать переполнения стека при глубокой рекурсии.
Также эффективно использовать стратегию «разбиение по медиане» для выбора опорного элемента. Это помогает избежать худших случаев, когда рекурсия может приводить к избыточным вызовам из-за неудачного выбора опорного элемента. Применение медианы как опорного элемента улучшает балансировку подмассивов, что уменьшает глубину рекурсии и снижает время работы алгоритма.
Ещё одной важной оптимизацией является использование «гибридного» подхода, где для маленьких массивов (обычно размером до 10-20 элементов) быстрая сортировка заменяется на сортировку вставками. Это значительно снижает количество рекурсивных вызовов на малых подмассивах, где быстрая сортировка не даёт значительного выигрыша.
Наконец, при проектировании алгоритма важно учитывать специфику данных. Если входные данные уже частично отсортированы или содержат много одинаковых элементов, стандартный алгоритм быстрой сортировки может давать неэффективные результаты. В таких случаях можно использовать различные подходы к выбору опорного элемента или другие алгоритмы сортировки (например, пирамидальную сортировку), которые могут существенно снизить количество рекурсивных вызовов.
Сравнение производительности быстрой сортировки и встроенной функции sort()
Быстрая сортировка имеет среднюю сложность O(n log n), но в худшем случае (когда данные почти отсортированы или отсортированы в обратном порядке) её сложность может быть O(n²). Встроенная функция sort() в Python всегда работает за O(n log n) в худшем случае благодаря алгоритму Timsort, который является гибридом сортировки слиянием и вставками. Timsort адаптируется к структуре данных, что позволяет избегать наихудшего времени выполнения.
Для небольших наборов данных различия в производительности между QuickSort и sort() минимальны. Однако, по мере увеличения объёма данных, sort() обычно работает быстрее благодаря своей адаптивности к различным ситуациям, таким как частично отсортированные или почти отсортированные данные. В то время как QuickSort может столкнуться с проблемами при таких условиях, Timsort в этом плане более надёжен.
Для очень больших массивов, когда данные сильно перемешаны, быстрая сортировка может быть несколько быстрее, если её реализовать с оптимизациями, например, с использованием случайного выбора опорного элемента. Однако, встроенная sort() всё равно будет показывать хорошую производительность в большинстве реальных сценариев благодаря внутренним оптимизациям и лучшему использованию памяти.
Рекомендации по выбору алгоритма: если требуется сортировка большого объёма данных или работа с частично отсортированными списками, лучше использовать sort(). Для задач, где важна скорость на случайных данных, и если алгоритм можно модифицировать, например, использовать случайный выбор опорного элемента, быстрая сортировка может быть эффективнее. Тем не менее, в большинстве случаев Python sort() продемонстрирует лучшую стабильность и производительность.
Работа с большими объёмами данных и ограничениями памяти
Алгоритм быстрой сортировки, несмотря на свою эффективность в большинстве случаев, может столкнуться с проблемами при работе с большими объёмами данных, особенно если доступная память ограничена. Этот аспект важно учитывать при выборе метода сортировки, поскольку быстрые сортировки используют рекурсию и могут вызвать переполнение стека при слишком глубокой рекурсии. Рассмотрим несколько методов оптимизации.
Одним из способов решения проблемы является использование хвостовой рекурсии. В Python рекурсия не оптимизирована, поэтому важно минимизировать количество рекурсивных вызовов. Для этого обычно используют стратегию, при которой меньшая из двух частей после разбиения массива на подмассивы сортируется рекурсивно, а большая – обрабатывается итеративно.
Другим важным аспектом является выбор подходящего алгоритма разбиения. Для работы с ограниченной памятью рекомендуется использовать алгоритм разбиения Hoare, который требует меньше памяти, чем разбиение Ломута, особенно в случае, когда массив состоит из большого количества элементов.
Для работы с большими объёмами данных на диске или в распределённых системах можно применять внешнюю сортировку, при которой данные делятся на блоки, сортируются по частям и затем сливаются. Для этого потребуется использование дополнительных структур данных, таких как временные файлы или базы данных, но в условиях ограниченной памяти это позволяет значительно уменьшить нагрузку на систему.
| Метод | Преимущества | Недостатки |
|---|---|---|
| Хвостовая рекурсия | Минимизация использования стека, предотвращение переполнения памяти | Не всегда эффективно, если доступная память сильно ограничена |
| Алгоритм разбиения Hoare | Меньше использования памяти по сравнению с Ломута | Может быть менее интуитивно понятен и труден в реализации |
| Внешняя сортировка | Подходит для обработки данных, которые не помещаются в память | Требует дополнительных ресурсов и времени на обработку файлов |
Для уменьшения потребления памяти также рекомендуется использовать эффективные структуры данных, такие как генераторы в Python, которые позволяют обрабатывать элементы по мере необходимости, а не хранить все данные в памяти одновременно. Это особенно полезно при работе с большими коллекциями данных.
В случае сортировки больших данных в распределённых системах стоит обратить внимание на алгоритмы, такие как MapReduce, которые эффективно распределяют задачи между несколькими узлами, снижая нагрузку на каждую отдельную машину. Это решение также помогает избежать переполнения памяти на одном узле.
Использование быстрой сортировки для объектов и кастомных ключей
Когда требуется отсортировать объекты, важно учитывать, что стандартная быстрая сортировка в Python работает только с примитивами или объектами, сравнимыми между собой. Однако с помощью кастомных ключей можно настроить сортировку для объектов любых типов, добавив нужные правила сравнения.
Для сортировки объектов с кастомными ключами используется параметр `key` в функции сортировки. Он позволяет задать функцию, которая будет применяться к каждому элементу при сравнении. В случае с быстрой сортировкой в Python это также можно реализовать через алгоритм `sorted()` или метод `.sort()`, которые по умолчанию используют алгоритм Timsort, но их можно адаптировать с помощью ключа.
Пример сортировки списка объектов по атрибуту:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
people = [Person('Alice', 30), Person('Bob', 25), Person('Charlie', 35)]
# Сортировка по возрасту
sorted_people = sorted(people, key=lambda person: person.age)
Здесь `lambda person: person.age` – это кастомный ключ, который извлекает значение возраста для сравнения. Важное замечание: ключи, использующие лямбда-функции, могут сильно повлиять на производительность, особенно при работе с большими наборами данных.
Также важно помнить, что Python использует Timsort, который является гибридным алгоритмом сортировки, и фактически реализует быструю сортировку, когда это возможно. Для кастомных объектов это означает, что если операция сравнения между объектами может быть выполнена эффективно (например, через числовые значения или строки), то скорость сортировки останется высокой.
Для более сложных объектов можно использовать несколько критериев сортировки. Например, для объектов с несколькими аттрибутами (имя и возраст) можно комбинировать несколько ключей:
# Сортировка сначала по имени, затем по возрасту sorted_people = sorted(people, key=lambda person: (person.name, person.age))
Для оптимизации работы с большими объемами данных стоит учитывать, что быстрые сортировки эффективны при большом числе элементов, однако при использовании сложных объектов и нескольких критериев может потребоваться дополнительные улучшения производительности, такие как использование кэширования или предварительной обработки данных.
Итак, использование быстрой сортировки с кастомными ключами позволяет гибко адаптировать алгоритм под нужды конкретных типов данных, сохраняя его высокую производительность при должной настройке ключей.
Вопрос-ответ:
Что такое быстрая сортировка в Python?
Быстрая сортировка (QuickSort) — это алгоритм сортировки, который работает на основе принципа «разделяй и властвуй». Он выбирает элемент из списка (обычно это опорный элемент) и разделяет все остальные элементы на две группы: меньше и больше опорного. После этого каждая из этих групп сортируется рекурсивно. В Python быстрая сортировка часто используется благодаря своей хорошей производительности при сортировке больших списков.
Как работает принцип разделения при быстрой сортировке?
При быстрой сортировке выбирается опорный элемент. Затем все элементы в списке перераспределяются так, чтобы слева от опорного элемента оказались те, которые меньше его, а справа — те, которые больше. Этот процесс называется разделением (partition). После разделения алгоритм рекурсивно сортирует левую и правую части списка, что позволяет быстро отсортировать весь массив.
Какая сложность алгоритма быстрой сортировки в худшем случае?
В худшем случае сложность алгоритма быстрой сортировки составляет O(n²). Это происходит, когда опорный элемент всегда оказывается самым большим или самым маленьким, что приводит к неравномерному разделению списка. Однако в среднем случае сложность быстрой сортировки составляет O(n log n), что делает её одним из самых быстрых алгоритмов для сортировки больших данных.
Можно ли улучшить работу быстрой сортировки в Python?
Да, можно. Одним из способов улучшения является использование медианы трех элементов в качестве опорного, что повышает вероятность сбалансированного разделения списка. Также стоит обратить внимание на базовые случаи рекурсии — если длина списка меньше определенного порога, лучше использовать другие алгоритмы сортировки, такие как сортировка вставками. Это позволяет ускорить выполнение алгоритма на небольших данных и уменьшить рекурсию.