Интеграция SQL с языком С требует понимания клиентских библиотек и протоколов взаимодействия с базой данных. Наиболее распространённый подход – использование библиотеки ODBC или драйверов конкретной СУБД, например MySQL Connector/C для MySQL и libpq для PostgreSQL. Эти инструменты обеспечивают прямой доступ к SQL-запросам и обработку результатов на уровне C-структур.
Для корректного соединения необходимо явно инициализировать соединение через функцию подключения драйвера, указав адрес сервера, имя базы данных, имя пользователя и пароль. В случае MySQL это функция mysql_real_connect(), а в PostgreSQL – PQconnectdb(). Ошибки на этом этапе нужно обрабатывать через специальные функции mysql_error() или PQerrorMessage(), чтобы избежать silent-fail сценариев.
После успешного соединения рекомендуется использовать подготовленные запросы (prepared statements) для предотвращения SQL-инъекций и повышения производительности. В MySQL это mysql_stmt_prepare(), а в PostgreSQL – PQprepare(). Для обработки результатов SQL-запросов удобно применять курсоры или структуры result sets, позволяющие итерироваться по строкам и столбцам без дополнительных преобразований.
Закрытие соединения должно быть явным и выполняться через функции mysql_close() или PQfinish(), освобождая ресурсы и предотвращая утечки памяти. Практика показывает, что строгая типизация переменных для данных из базы снижает вероятность ошибок при преобразовании типов SQL и C, особенно при работе с датами, числами с плавающей точкой и текстовыми полями.
Выбор библиотеки для работы с SQL в С
Если требуется кроссплатформенность и совместимость с несколькими СУБД, стоит обратить внимание на ODBC через unixODBC или iODBC. ODBC позволяет единообразно работать с MySQL, PostgreSQL, SQLite и Oracle, но накладывает небольшую нагрузку на производительность из-за универсального интерфейса.
Для встроенных решений и минимального объема зависимостей предпочтительна SQLite с библиотекой sqlite3.h, обеспечивающей хранение базы в одном файле, транзакции ACID и возможность работы без отдельного сервера.
При выборе библиотеки учитывайте наличие документации, активность поддержки и совместимость с современными стандартами C (C99 и выше). В проектах с высокими требованиями к скорости лучше использовать нативные API конкретной СУБД, в гибких мультисистемных приложениях – ODBC, а для локальных легковесных баз – SQLite.
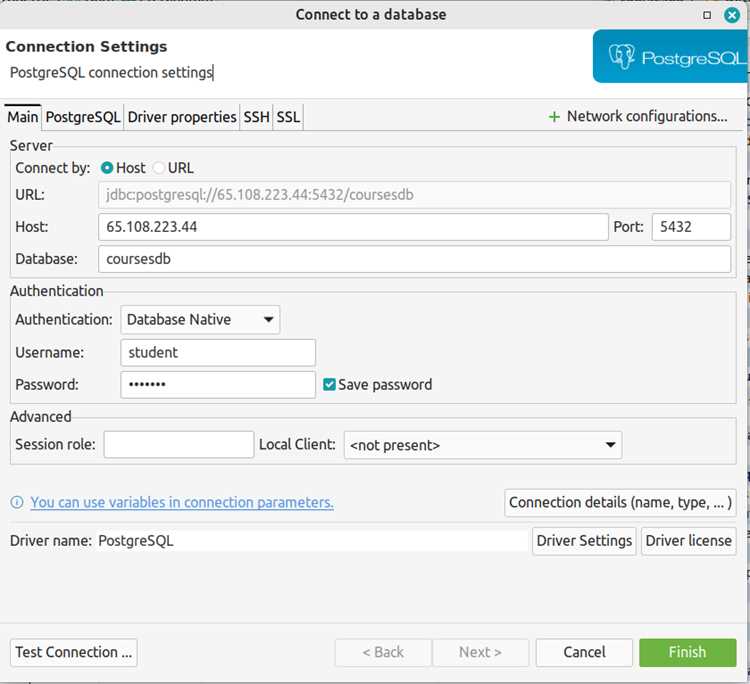
Настройка окружения и подключение к серверу базы данных

Для работы с SQL в C необходимо установить клиентскую библиотеку выбранной СУБД. Для MySQL это libmysqlclient, для PostgreSQL – libpq. На Linux используйте пакетный менеджер: sudo apt install libmysqlclient-dev или sudo apt install libpq-dev. На Windows требуется скачать DLL и заголовочные файлы с официального сайта СУБД.
В C проекте подключите заголовочные файлы библиотеки: #include <mysql.h> для MySQL или #include <libpq-fe.h> для PostgreSQL. Для компиляции укажите линковку с библиотекой: gcc main.c -lmysqlclient или gcc main.c -lpq.
Перед соединением создайте структуру соединения и инициализируйте библиотеку: для MySQL используйте MYSQL *conn = mysql_init(NULL);, для PostgreSQL – PGconn *conn = PQconnectdb("host=localhost dbname=test user=user password=pass");. Проверяйте результат подключения: MySQL – if (!mysql_real_connect(...)) { fprintf(stderr, "%s\n", mysql_error(conn)); }, PostgreSQL – if (PQstatus(conn) != CONNECTION_OK) { fprintf(stderr, "%s\n", PQerrorMessage(conn)); }.
Для обеспечения безопасности используйте явное указание хоста, порта и кодировки, избегайте хранения паролей в исходном коде. Настройте тайм-ауты соединения и обработку ошибок: MySQL – mysql_options(conn, MYSQL_OPT_CONNECT_TIMEOUT, &timeout);, PostgreSQL – параметр connect_timeout в строке подключения.
После успешного подключения можно переходить к выполнению запросов. Закрывайте соединение через mysql_close(conn); для MySQL и PQfinish(conn); для PostgreSQL, чтобы освободить ресурсы.
Создание и закрытие соединения из программы на С
Для подключения к базе данных SQL из программы на C чаще всего используется библиотека libmysqlclient для MySQL или sqlite3 для SQLite. Процесс включает инициализацию библиотеки, установку соединения, выполнение запросов и корректное завершение работы с соединением.
Пример создания соединения с MySQL:
- Подключение заголовочного файла:
#include <mysql/mysql.h> - Инициализация структуры соединения:
MYSQL *conn = mysql_init(NULL); - Установка соединения с сервером:
mysql_real_connect(conn, "localhost", "user", "password", "database", 3306, NULL, 0);- Проверка успешности соединения:
if (conn == NULL) { fprintf(stderr, "Ошибка подключения: %s\n", mysql_error(conn)); } - Выполнение SQL-запросов через
mysql_query(conn, "SQL-запрос");
Для SQLite процесс проще, так как соединение создаётся с файлом базы данных:
- Подключение заголовочного файла:
#include <sqlite3.h> - Создание соединения:
sqlite3 *db; sqlite3_open("database.db", &db); - Проверка успешности:
if (db == NULL) { fprintf(stderr, "Не удалось открыть базу\n"); }
Закрытие соединения должно быть обязательным шагом после завершения работы с базой данных, чтобы избежать утечек памяти и блокировок:
- Для MySQL:
mysql_close(conn); - Для SQLite:
sqlite3_close(db);
Рекомендации по безопасности и стабильности:
- Использовать проверку ошибок после каждой функции работы с соединением.
- Закрывать соединение в блоке
finallyили после всех операций, чтобы не оставлять открытые дескрипторы. - При многопоточном доступе использовать отдельные соединения для каждого потока или библиотечные механизмы синхронизации.
Выполнение простых SQL-запросов через С
Для выполнения SQL-запросов из программы на С используется библиотека SQLite или API конкретной СУБД, например MySQL Connector/C. Начало работы требует подключения заголовочного файла и инициализации соединения с базой данных с помощью функции sqlite3_open() или mysql_real_connect().
Запросы на чтение выполняются через функции sqlite3_exec() или mysql_query(). В SQLite для получения результатов используют callback-функцию, которая получает количество столбцов, массив значений и имена колонок. В MySQL обработка результата осуществляется через MYSQL_RES и функции mysql_store_result(), mysql_fetch_row().
Пример выполнения запроса SELECT в SQLite: sqlite3_exec(db, "SELECT id, name FROM users;", callback, 0, &err_msg);, где callback обрабатывает каждую строку результата. Для запросов INSERT, UPDATE или DELETE достаточно проверить возвращаемое значение функции, чтобы убедиться в успешном выполнении операции.
При работе с параметризованными запросами рекомендуется использовать подготовленные выражения через sqlite3_prepare_v2() и sqlite3_bind_text() или аналогичные функции MySQL mysql_stmt_prepare() и mysql_stmt_bind_param(). Это повышает безопасность и предотвращает SQL-инъекции.
После завершения работы с базой необходимо корректно закрыть соединение с помощью sqlite3_close() или mysql_close() и освобождать память, выделенную для результатов запроса, через sqlite3_finalize() или mysql_free_result().
При планировании выполнения нескольких последовательных запросов рекомендуется использовать транзакции через BEGIN TRANSACTION и COMMIT в SQLite или START TRANSACTION и COMMIT в MySQL, что повышает производительность и предотвращает частичное выполнение операций.
Обработка результатов выборки в массивы и структуры

После выполнения SQL-запроса через C необходимо корректно извлечь данные из результата. Для этого используют массивы и структуры, что обеспечивает удобное хранение и дальнейшую обработку.
Для строковых данных создают массивы символов фиксированной длины, например: char name[50]. Для числовых полей используют стандартные типы: int, double, float. Если запись состоит из нескольких полей, удобно определить структуру:
Пример структуры для таблицы сотрудников:
typedef struct { int id; char name[50]; double salary; } Employee;
После выполнения запроса, полученный результат можно обходить с помощью функций API базы данных, например sqlite3_step() для SQLite или mysql_fetch_row() для MySQL. Каждый вызов возвращает одну строку, которую присваивают полям структуры или элементам массива структур.
Пример заполнения массива структур из результата запроса MySQL:
MYSQL_ROW row; Employee employees[100]; int i = 0;
while ((row = mysql_fetch_row(res))) {
employees[i].id = atoi(row[0]);
strncpy(employees[i].name, row[1], 50);
employees[i].salary = atof(row[2]);
i++;
}
Рекомендуется контролировать размер массивов и использовать функции конверсии типов, чтобы избежать переполнения и ошибок преобразования. Для динамических объемов данных применяют выделение памяти через malloc и realloc, что позволяет адаптироваться под количество строк в выборке.
Использование структур повышает читаемость кода и упрощает доступ к отдельным полям, а массивы структур позволяют эффективно хранить и сортировать результаты без дополнительных преобразований.
Обработка ошибок соединения и выполнения запросов
При работе с SQL из языка C критически важно отслеживать ошибки на каждом этапе: от установления соединения до выполнения SQL-запросов. Функции подключения, такие как mysql_real_connect() для MySQL или PQconnectdb() для PostgreSQL, возвращают указатели на структуру соединения или NULL при ошибке. Проверка результата должна выполняться сразу после вызова функции.
Пример проверки соединения с MySQL:
MYSQL *conn = mysql_init(NULL);
if (!conn) {
fprintf(stderr, "Ошибка инициализации: %s\n", mysql_error(conn));
exit(EXIT_FAILURE);
}
if (!mysql_real_connect(conn, host, user, passwd, dbname, 0, NULL, 0)) {
fprintf(stderr, "Ошибка соединения: %s\n", mysql_error(conn));
mysql_close(conn);
exit(EXIT_FAILURE);
}
При выполнении запросов через mysql_query() или PQexec() ошибки можно фиксировать с помощью соответствующих функций возврата статуса. Для MySQL статус 0 указывает на успешное выполнение, любой другой код – на ошибку. В PostgreSQL проверка выполняется по значению PQresultStatus(result).
| Действие | Метод проверки | Действие при ошибке |
|---|---|---|
| Соединение с сервером | mysql_real_connect(), PQstatus() |
Вывести текст ошибки, закрыть соединение, завершить программу |
| Выполнение запроса | mysql_query(), PQexec() |
Вывести код и текст ошибки, при необходимости выполнить ROLLBACK |
| Получение результата | mysql_store_result(), PQgetResult() |
Проверить NULL, освободить ресурсы, зафиксировать лог |
Для повышения надежности рекомендуется использовать детализированные сообщения об ошибках, включая код ошибки и строку запроса. Это облегчает отладку сложных SQL-операций и предотвращает утечку ресурсов при неожиданном завершении программы.
Важный прием – проверка возвращаемых указателей на NULL перед использованием, а также освобождение выделенной памяти и закрытие соединений с помощью mysql_close() или PQfinish() для предотвращения утечек ресурсов.
Передача параметров в запросы для динамической работы с данными
Для динамической работы с SQL-базами из C важно использовать подготовленные выражения (prepared statements) и параметризацию запросов. Это снижает риск SQL-инъекций и упрощает изменение значений без пересборки строки запроса.
В стандартной библиотеке ODBC и в драйверах для MySQL или PostgreSQL создаются объекты `stmt` через функцию `SQLAllocHandle`. После этого выполняется `SQLPrepare`, куда передается текст запроса с параметрами в виде `?` для ODBC или `$1, $2…` для PostgreSQL. Пример для ODBC:
SQLPrepare(stmt, "SELECT * FROM users WHERE age > ?", SQL_NTS);
Затем параметры связываются с переменными C через `SQLBindParameter`. Тип данных указывается явно, например, `SQL_C_LONG` для целых чисел, `SQL_C_CHAR` для строк. Это позволяет корректно передавать значения различных типов без преобразований вручную.
int age = 30;
SQLBindParameter(stmt, 1, SQL_PARAM_INPUT, SQL_C_LONG, SQL_INTEGER, 0, 0, &age, 0, NULL);
Для обновления или вставки данных используется аналогичный подход. Например, для MySQL с использованием `mysql_stmt_bind_param` создается массив `MYSQL_BIND`, куда помещаются адреса переменных и их типы. После вызова `mysql_stmt_execute` значения подставляются в запрос автоматически.
При динамическом формировании запросов важно: использовать только привязанные параметры, избегать конкатенации строк с пользовательским вводом, контролировать соответствие типов данных между C и SQL, а также освобождать ресурсы через `SQLFreeHandle` или `mysql_stmt_close` после выполнения запросов.
Эта методика обеспечивает безопасное масштабирование запросов, упрощает повторное использование одного SQL-запроса с разными значениями и минимизирует накладные расходы на парсинг и компиляцию запросов на сервере базы данных.
Вопрос-ответ:
Как можно подключить базу данных SQL к программе на С?
Для подключения базы данных SQL к программе на языке С чаще всего используют специализированные библиотеки, например, ODBC или MySQL C API. Процесс включает подключение к серверу базы данных с помощью строки соединения, авторизацию пользователя и выбор базы данных. После этого можно выполнять запросы и получать результаты.
Какие функции C используются для выполнения SQL-запросов?
В зависимости от выбранной библиотеки функции могут отличаться. Например, в MySQL C API применяются функции mysql_query() для отправки запроса, mysql_store_result() для получения результатов и mysql_fetch_row() для перебора строк таблицы. Эти функции позволяют управлять данными в базе напрямую из кода на С.
Как обработать ошибки при работе с базой данных в С?
Ошибки можно отлавливать с помощью встроенных функций библиотеки. В MySQL C API для этого существует mysql_error(), которая возвращает текст последней ошибки. Также рекомендуется проверять коды возврата функций, чтобы программа корректно реагировала на сбои подключения, ошибки синтаксиса запросов или проблемы с доступом к таблицам.
Можно ли передавать параметры в SQL-запросы из программы на С безопасно?
Да, для этого используются подготовленные выражения (prepared statements). Они позволяют задавать SQL-запрос с плейсхолдерами, а затем безопасно подставлять значения переменных. В MySQL C API применяются функции mysql_stmt_prepare(), mysql_stmt_bind_param() и mysql_stmt_execute(), которые предотвращают ошибки и повышают устойчивость программы к SQL-инъекциям.
Какие типы данных SQL поддерживаются при работе с C?
При работе с базой данных через C доступны стандартные SQL-типы, такие как INTEGER, VARCHAR, DATE, FLOAT и другие. Для каждой строки результата можно получить данные как массив символов или преобразовать в соответствующий тип C (int, double, char[]). Важно учитывать соответствие типов и правильно обрабатывать NULL значения, чтобы избежать сбоев программы.
Как подключить базу данных SQL к программе на языке С?
Для подключения к базе данных SQL из программы на языке С обычно используют специальные библиотеки, предоставляющие API для работы с SQL-сервером. Например, для работы с MySQL используют библиотеку MySQL Connector/C. Сначала необходимо подключить заголовочные файлы библиотеки и инициализировать соединение с сервером, указав адрес сервера, имя пользователя, пароль и имя базы данных. После установления соединения можно выполнять SQL-запросы с помощью функций библиотеки, получать результаты и обрабатывать их в программе. После завершения работы важно корректно закрыть соединение, чтобы освободить ресурсы. Этот подход позволяет создавать программы на С, которые могут выполнять выборку, обновление и удаление данных в базе данных, сохраняя структуру и типы данных, предусмотренные SQL.