Для точного подсчета количества записей в таблице SQL используется стандартная команда COUNT(). Она позволяет быстро получить количество строк, соответствующих определенным критериям, или всех строк в таблице без фильтрации.
Простой запрос для подсчета всех записей в таблице выглядит так:
SELECT COUNT(*) FROM имя_таблицы;Этот запрос вернет общее количество строк в указанной таблице. Однако важно помнить, что COUNT(*) учитывает все строки, включая те, где значения могут быть NULL. Если нужно подсчитать только строки с определенными значениями в одном из столбцов, можно использовать условие WHERE:
SELECT COUNT(*) FROM имя_таблицы WHERE условие;Вместо * можно указать конкретное поле для подсчета, например, COUNT(столбец). Этот запрос исключит строки с NULL в указанном поле, что может быть полезно в определенных сценариях:
SELECT COUNT(столбец) FROM имя_таблицы;Если требуется подсчитать количество уникальных значений в столбце, можно использовать COUNT(DISTINCT столбец). Этот подход полезен для анализа распределения данных и уникальности записей:
SELECT COUNT(DISTINCT столбец) FROM имя_таблицы;Каждый из этих методов имеет свои преимущества и ограничения, и выбор подходящего зависит от специфики задачи и структуры данных в таблице.
Использование команды COUNT() для подсчета всех записей
Функция COUNT() используется для подсчета числа строк в таблице или по заданным условиям. Этот запрос часто применяется для анализа количества данных в таблице, что может быть полезно при оценке объема информации или анализе распределения данных по категориям.
Основной синтаксис команды выглядит следующим образом:
SELECT COUNT(*) FROM имя_таблицы;Здесь COUNT(*) возвращает общее количество строк в таблице. Применение * означает подсчет всех строк, включая те, которые содержат NULL значения. Если необходимо подсчитать только строки с ненулевыми значениями в конкретном столбце, используется следующий вариант:
SELECT COUNT(имя_столбца) FROM имя_таблицы;В этом случае будут подсчитаны только те строки, где в столбце имя_столбца присутствуют значения, отличные от NULL. Это может быть полезно, например, для подсчета количества записей с конкретными данными.
Можно добавить условие для выборки только тех строк, которые соответствуют определенному критерию. Пример с условием WHERE:
SELECT COUNT(*) FROM имя_таблицы WHERE условие;Этот запрос вернет количество строк, удовлетворяющих условию. Например, чтобы подсчитать количество заказов, выполненных после определенной даты, можно использовать такой запрос:
SELECT COUNT(*) FROM заказы WHERE дата_заказа > '2025-01-01';Также COUNT() может использоваться в сочетании с группировкой. Это позволяет подсчитывать количество строк в каждой группе, что полезно для анализа распределения данных по категориям. Пример с группировкой по статусу заказов:
SELECT статус_заказа, COUNT(*) FROM заказы GROUP BY статус_заказа;В этом запросе будет выведено количество заказов для каждого статуса, что позволяет быстро оценить распределение заказов по состоянию их выполнения.
Функция COUNT() работает эффективно на индексированных таблицах и может быть полезна для различных аналитических задач, таких как статистика и мониторинг активности пользователей или транзакций.
Как подсчитать количество записей с условием WHERE
Чтобы посчитать количество записей в таблице с определёнными условиями, используется SQL-запрос с конструкцией COUNT() и фильтром WHERE. Эта комбинация позволяет отфильтровывать данные перед подсчётом.
Простейший запрос выглядит так:
SELECT COUNT(*) FROM таблица WHERE условие;Вместо * можно указать конкретное поле, если нужно подсчитать количество уникальных значений в этом поле:
SELECT COUNT(поле) FROM таблица WHERE условие;Пример запроса для подсчёта количества заказов от клиента с определённым статусом:
SELECT COUNT(*) FROM заказы WHERE статус = 'Завершён';При использовании WHERE можно комбинировать различные условия:
ANDдля добавления нескольких условий (например, фильтрация по дате и статусу):
SELECT COUNT(*) FROM заказы WHERE статус = 'Завершён' AND дата_заказа > '2023-01-01';OR для альтернативных условий (например, подсчёт заказов с одним из нескольких статусов):SELECT COUNT(*) FROM заказы WHERE статус = 'Завершён' OR статус = 'Отменён';Использование COUNT() с условием WHERE помогает исключить записи, не соответствующие критериям, и получить точные результаты подсчёта.
Применение DISTINCT для подсчета уникальных значений
Оператор DISTINCT в SQL позволяет выбирать только уникальные значения из столбца или комбинации столбцов. Это полезно, когда необходимо подсчитать количество различных записей, исключив повторения.
Для подсчета уникальных значений используется конструкция COUNT с DISTINCT. Пример запроса:
SELECT COUNT(DISTINCT column_name) FROM table_name;Здесь COUNT возвращает количество уникальных значений в столбце column_name таблицы table_name. Это особенно полезно, если в таблице содержатся повторяющиеся данные, и вам нужно определить, сколько уникальных значений присутствует.
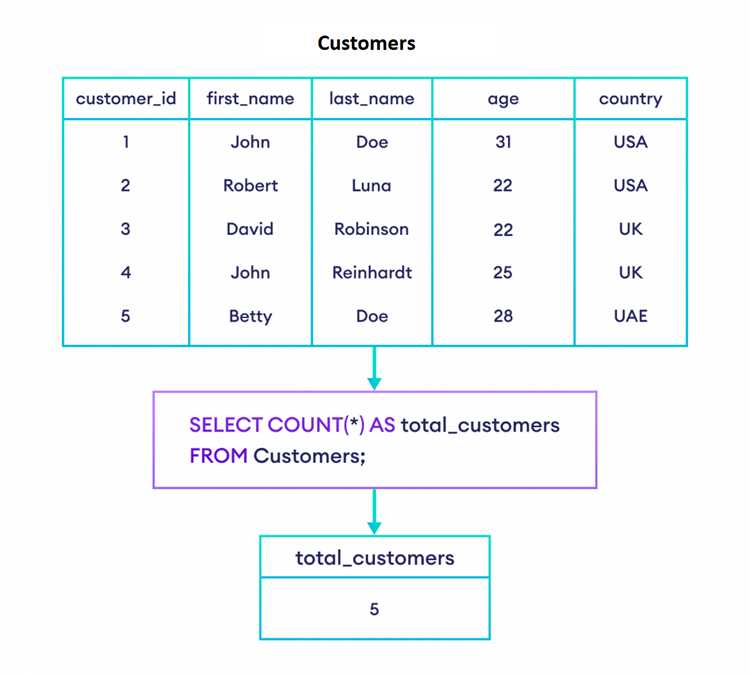
Пример таблицы «orders»:
| order_id | customer_id |
|---|---|
| 1 | 101 |
| 2 | 102 |
| 3 | 101 |
| 4 | 103 |
| 5 | 102 |
Чтобы подсчитать количество уникальных покупателей (customer_id) в таблице «orders», можно использовать следующий запрос:
SELECT COUNT(DISTINCT customer_id) FROM orders;Этот запрос вернет значение 3, поскольку в таблице три уникальных customer_id: 101, 102 и 103.
Важно помнить, что DISTINCT работает не только для одного столбца, но и для нескольких. Например, если вам нужно узнать количество уникальных комбинаций заказов и покупателей, используйте:
SELECT COUNT(DISTINCT order_id, customer_id) FROM orders;Этот запрос вернет количество уникальных пар заказов и покупателей, что может быть полезно для анализа уникальных взаимодействий в системе.
Подсчет записей с группировкой данных по колонкам
Для подсчета количества записей с группировкой данных по колонкам в SQL используется оператор GROUP BY. Он позволяет агрегировать данные по указанным столбцам, что полезно, когда необходимо узнать количество записей для каждой группы. Например, подсчет количества заказов по каждой категории товаров.
Основной запрос выглядит так:
SELECT колонка1, COUNT(*)
FROM таблица
GROUP BY колонка1;Пример: подсчитаем количество заказов для каждой категории товаров:
SELECT категория, COUNT(*)
FROM заказы
GROUP BY категория;В этом примере результат будет содержать список категорий товаров и количество заказов для каждой категории.
Для группировки по нескольким столбцам можно использовать несколько колонок в GROUP BY:
SELECT колонка1, колонка2, COUNT(*)
FROM таблица
GROUP BY колонка1, колонка2;Пример: подсчитаем количество заказов по каждому клиенту и категории товара:
SELECT клиент, категория, COUNT(*)
FROM заказы
GROUP BY клиент, категория;Если необходимо отсортировать результаты по количеству записей, используйте оператор ORDER BY:
SELECT категория, COUNT(*)
FROM заказы
GROUP BY категория
ORDER BY COUNT(*) DESC;Чтобы исключить группы с нулевым значением, можно применить фильтрацию с помощью HAVING, которая действует после группировки:
SELECT категория, COUNT(*)
FROM заказы
GROUP BY категория
HAVING COUNT(*) > 5;В результате такого запроса будут показаны только те категории товаров, где количество заказов больше 5.
Таким образом, для подсчета записей с группировкой важно учитывать:
- Использование
GROUP BYдля группировки по нужным колонкам. - Применение
HAVINGдля фильтрации по агрегированным данным. - Сортировку результатов с помощью
ORDER BY.
Определение числа записей с использованием JOIN
Простой пример запроса, который использует JOIN для подсчёта количества строк в двух таблицах:
SELECT COUNT(*) FROM orders AS o JOIN customers AS c ON o.customer_id = c.customer_id;
В этом запросе соединяются таблицы orders и customers по полю customer_id, а затем с помощью COUNT(*) подсчитывается общее количество строк, удовлетворяющих условию соединения.
Если требуется учесть только уникальные записи из одной из таблиц, можно использовать DISTINCT:
SELECT COUNT(DISTINCT o.order_id) FROM orders AS o JOIN customers AS c ON o.customer_id = c.customer_id;
Если нужно подсчитать количество записей в случае наличия или отсутствия соответствующих записей в обеих таблицах, можно использовать LEFT JOIN или RIGHT JOIN:
SELECT COUNT(*) FROM orders AS o LEFT JOIN customers AS c ON o.customer_id = c.customer_id;
Этот запрос посчитает все заказы, включая те, которые не имеют соответствующего клиента в таблице customers. Использование LEFT JOIN важно, если важно сохранить все записи из одной из таблиц (в данном случае – из таблицы orders), даже если в другой таблице нет соответствующих данных.
Если необходимо подсчитать количество строк, где есть хотя бы один подходящий элемент в обеих таблицах, стоит использовать INNER JOIN. Это ограничит выборку только теми записями, которые имеют соответствие в обеих таблицах:
SELECT COUNT(*) FROM orders AS o INNER JOIN customers AS c ON o.customer_id = c.customer_id;
Также, в случае сложных соединений, может быть полезно использовать GROUP BY для подсчёта записей по категориям. Например, подсчёт заказов по каждому клиенту:
SELECT c.customer_id, COUNT(*) FROM orders AS o JOIN customers AS c ON o.customer_id = c.customer_id GROUP BY c.customer_id;
Этот запрос возвращает количество заказов для каждого клиента, что полезно для анализа данных и создания отчетности.
Использование подзапросов для подсчета записей в сложных запросах
Одним из основных подходов является использование подзапросов в SELECT или FROM частях запроса. Например, можно использовать подзапрос в SELECT для подсчета записей, соответствующих определенному условию, внутри основного запроса. Это позволяет работать с агрегированными данными на разных уровнях.
Пример 1: Подсчет количества записей в подзапросе для выбора только тех записей, где количество строк в подтаблице превышает заданный порог:
SELECT main_table.id, (SELECT COUNT(*) FROM sub_table WHERE sub_table.main_id = main_table.id) AS record_count FROM main_table;
В этом примере основной запрос возвращает записи из таблицы main_table, а подзапрос считает количество записей в sub_table, связанные с каждым элементом основной таблицы. Это позволяет динамически подсчитывать количество записей, соответствующих конкретным условиям.
Для более сложных запросов можно использовать подзапросы в FROM части, что позволяет выполнять агрегацию данных до основного подсчета. Такой подход полезен, если необходимо выполнить агрегацию или фильтрацию перед подсчетом.
Пример 2: Использование подзапроса для фильтрации данных до выполнения подсчета:
SELECT COUNT(*) FROM (SELECT id FROM users WHERE registration_date > '2023-01-01') AS filtered_users;
Здесь подзапрос сначала фильтрует пользователей по дате регистрации, а основной запрос подсчитывает количество отфильтрованных записей. Такой подход может быть полезен, если фильтрация и подсчет происходят в разных частях запроса.
В случаях, когда необходимо учесть более сложные условия, можно комбинировать несколько подзапросов, что позволит выполнять агрегацию и фильтрацию по разным критериям одновременно. Например, можно использовать подзапросы для подсчета количества записей по разным условиям в разных таблицах или использовать их для получения статистики по взаимосвязанным данным.
Пример 3: Подсчет количества записей по нескольким условиям с использованием нескольких подзапросов:
SELECT main_table.id, (SELECT COUNT(*) FROM sub_table1 WHERE sub_table1.main_id = main_table.id) AS count_1, (SELECT COUNT(*) FROM sub_table2 WHERE sub_table2.main_id = main_table.id) AS count_2 FROM main_table;
Этот пример показывает, как можно использовать несколько подзапросов для подсчета количества записей по разным условиям в разных таблицах. Это особенно полезно, если необходимо сравнивать данные по различным критериям или учитывать дополнительные связи между таблицами.
Подзапросы – это мощный инструмент, но важно помнить, что их использование может снизить производительность, особенно если запросы выполняются на больших объемах данных. Поэтому рекомендуется использовать подзапросы только в случае, когда они необходимы для корректного выполнения запроса, и оптимизировать запросы, чтобы избежать избыточных вычислений.
Как получить количество строк в большой таблице с минимальными затратами
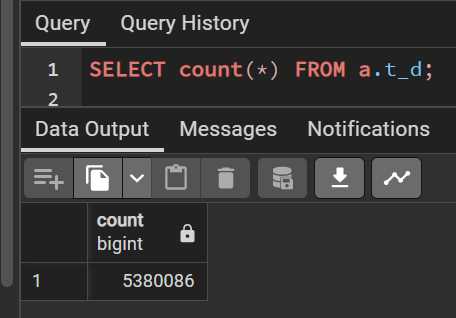
Для получения точного количества строк в большой таблице SQL существует несколько методов, но некоторые из них могут быть значительно более ресурсоемкими. Наиболее эффективный способ зависит от требований к точности и времени отклика.
1. Использование системных метаданных
Некоторые СУБД поддерживают хранение статистики о количестве строк в таблице. Например, в MySQL можно использовать команду SHOW TABLE STATUS, которая возвращает количество строк для каждой таблицы в базе данных. Этот метод минимизирует нагрузку на систему, так как не выполняет полноценный подсчёт, а лишь извлекает информацию из метаданных.
Пример запроса для MySQL:
SHOW TABLE STATUS LIKE 'имя_таблицы';Этот метод работает быстро, но важно учитывать, что статистика может быть устаревшей, если данные в таблице изменялись недавно.
2. Использование индексированных колонок
Если таблица имеет индекс, который охватывает большинство записей (например, по уникальному идентификатору), можно использовать этот индекс для подсчёта строк. В некоторых случаях это может быть быстрее, чем полный подсчёт, так как индексы часто оптимизированы для быстрого поиска.
Пример запроса для PostgreSQL:
SELECT COUNT(*) FROM имя_таблицы;При этом важно понимать, что в случае очень больших таблиц такой запрос может всё же занять значительное время, особенно если таблица не имеет индексов, соответствующих условиям запроса.
3. Использование разделения таблицы (Partitioning)
Если таблица очень большая, можно ускорить подсчёт строк с помощью разделения данных на части (партиционирование). Разделив таблицу по определённым критериям (например, по датам или диапазонам значений), можно выполнить подсчёт по каждой части, а затем суммировать результаты. Это позволит снизить нагрузку на систему и ускорить процесс подсчёта.
Пример запроса для подсчёта в нескольких партициях:
SELECT SUM(cnt) FROM (SELECT COUNT(*) as cnt FROM имя_таблицы PARTITION (partition_1) UNION ALL SELECT COUNT(*) as cnt FROM имя_таблицы PARTITION (partition_2)) as t;4. Использование многозадачности
Если таблица очень большая, можно использовать многозадачность для параллельного подсчёта строк. Это позволит распределить нагрузку на несколько потоков и ускорить выполнение запроса. Такие методы могут быть реализованы через обработку данных в нескольких процессах или с использованием параллельных вычислений на уровне СУБД (например, в PostgreSQL с помощью параметра max_parallel_workers_per_gather).
5. Использование Estimate
Если требуется лишь оценка количества строк (без точности), можно использовать команду для оценки статистики, такую как EXPLAIN в PostgreSQL. Она предоставляет приблизительную информацию о числе строк, что значительно быстрее и требует меньше ресурсов, чем полный подсчёт.
Пример запроса:
EXPLAIN SELECT * FROM имя_таблицы;Этот метод хорошо подходит для случаев, когда точное количество не критично, но нужна быстрая оценка.