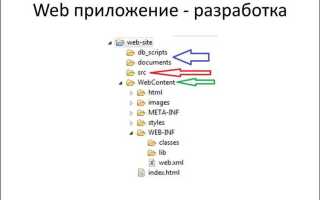
Веб-приложение на Java строится вокруг сервлетов, которые обрабатывают HTTP-запросы и формируют ответы. Для стабильной работы важно правильно настроить контейнер сервлетов, такой как Apache Tomcat или Jetty, и оптимизировать пул потоков, чтобы предотвратить блокировки при высоких нагрузках.
Обработка запросов реализуется через методы doGet и doPost. Для обеспечения масштабируемости рекомендуется разделять логику представления и бизнес-логику, используя паттерн MVC. Контроллеры управляют потоком данных, а сервисный слой отвечает за обработку и хранение информации.
Управление состоянием выполняется через сессии и куки. Для высоконагруженных приложений стоит применять распределённое кэширование, например, Redis, чтобы снизить нагрузку на базу данных. Правильная настройка таймаутов и механизма очистки сессий предотвращает утечки памяти.
Работа с базой данных организуется через JDBC или ORM-фреймворки, такие как Hibernate. Важно использовать подготовленные выражения и управление транзакциями, чтобы обеспечить целостность данных и защиту от SQL-инъекций. Пул соединений, например HikariCP, повышает производительность при одновременных запросах.
Безопасность веб-приложения обеспечивается через шифрование соединений (HTTPS), фильтры для проверки входных данных и управление правами доступа на уровне сервлетов и сервисного слоя. Регулярный аудит кода и внедрение механизма логирования помогают оперативно выявлять уязвимости и ошибки.
Принципы работы веб-приложения на Java

Веб-приложение на Java строится на основе архитектуры клиент-сервер. Серверная часть реализуется с использованием Java EE или Jakarta EE, Spring Boot, либо других фреймворков, предоставляющих инфраструктуру для обработки HTTP-запросов, управления сессиями и взаимодействия с базой данных.
Основным элементом сервера является сервлет, который принимает HTTP-запрос, обрабатывает его и формирует ответ. Серверная логика часто разделяется на слои: контроллеры обрабатывают запросы, сервисы реализуют бизнес-логику, DAO-слой управляет доступом к данным.
Веб-приложение использует следующие протоколы и форматы:
| Компонент | Назначение |
|---|---|
| HTTP/HTTPS | Передача запросов и ответов между клиентом и сервером |
| JSON/XML | Формат передачи данных между фронтендом и бэкендом |
| JDBC | Доступ к реляционным базам данных |
| WebSocket | Поддержка двусторонней связи в реальном времени |
Для управления состоянием используется сессия, идентифицируемая уникальным идентификатором, хранящимся в cookie или URL. Java-фреймворки предоставляют средства автоматического связывания данных формы с объектами и валидации введенных пользователем значений.
Обработка ошибок реализуется через исключения и фильтры сервлета, которые позволяют централизованно логировать сбои и отправлять корректные ответы клиенту. Рекомендуется применять шаблоны проектирования, такие как MVC и DAO, для повышения модульности и упрощения поддержки кода.
Производительность обеспечивается кэшированием данных, пулом соединений с базой данных, асинхронной обработкой запросов и оптимизацией SQL-запросов. Безопасность поддерживается с помощью шифрования HTTPS, контроля доступа через роли и проверки входных данных для предотвращения SQL-инъекций и XSS-атак.
Настройка сервера и деплой Java-приложения
Для стабильной работы Java-приложения критически важно правильно настроить сервер и выбрать подходящий способ деплоя. Рассмотрим последовательность действий и рекомендации.
Выбор сервера
- Для Java-приложений обычно используют Apache Tomcat, Jetty или WildFly. Tomcat подходит для легких веб-приложений, WildFly – для корпоративных проектов с EJB и JMS.
- Убедитесь, что версия JDK сервера совпадает с версией, использованной при сборке приложения.
- Настройка системных переменных: JAVA_HOME должен указывать на корень JDK, а PATH – содержать bin-папку JDK.
Подготовка к деплою
- Соберите приложение в формат WAR с помощью Maven или Gradle.
- Проверьте конфигурацию
web.xmlи файлыapplication.propertiesилиapplication.ymlна соответствие окружению. - Оптимизируйте логику приложения для многопоточности и минимизации потребления памяти.
Настройка сервера
- Создайте отдельный каталог для приложения в
webappsTomcat или аналогичной директории другого сервера. - Настройте
server.xmlилиstandalone.xml: укажите порт, контекстное имя и размеры пула соединений. - Для продакшн-среды установите ограничения на память JVM через параметры
-Xmsи-Xmx, например-Xms512m -Xmx2g. - Настройте логирование через Logback или Log4j с ротацией файлов и разделением по уровням.
Деплой приложения
- Скопируйте WAR-файл в папку
webappsсервера и перезапустите его. - При необходимости используйте автоматический деплой через CI/CD (Jenkins, GitLab CI), настроив шаги сборки и копирования WAR.
- Проверьте доступность приложения по URL и корректность загрузки всех ресурсов.
- Используйте утилиты мониторинга (VisualVM, JConsole) для анализа потребления ресурсов после запуска.
Дополнительные рекомендации
- Разделяйте окружения: DEV, TEST, PROD с разными конфигурациями и базами данных.
- Обновляйте сервер и библиотеки до последних патчей безопасности.
- Настройте автоматический бэкап WAR-файлов и конфигураций перед обновлением приложения.
Обработка HTTP-запросов и маршрутизация в сервлетах

В сервлетах обработка HTTP-запросов строится на методах doGet(), doPost(), doPut() и doDelete(), реализованных в классе, наследующем HttpServlet. Каждый метод получает объекты HttpServletRequest и HttpServletResponse, которые предоставляют полный доступ к данным запроса и средствам формирования ответа.
Ключевые действия при обработке запроса:
- Извлечение параметров:
request.getParameter("name"),request.getParameterValues("items"). - Работа с заголовками:
request.getHeader("User-Agent"),request.getHeaders("Accept"). - Управление сессиями:
request.getSession()для сохранения данных между запросами. - Формирование ответа:
response.setContentType("application/json"),response.getWriter().write(json).
Маршрутизация в сервлетах определяется аннотацией @WebServlet("/path") или элементом <servlet-mapping> в web.xml. Параметры маршрута могут быть статическими или динамическими с использованием шаблонов, например: /users/*.
Для точной маршрутизации рекомендуется:
- Использовать разные сервлеты для различных ресурсов и HTTP-методов.
- Применять регулярные выражения или паттерны URL для фильтрации запросов.
- Обрабатывать ошибки и отсутствующие ресурсы через
response.sendError(404)или собственные страницы ошибок. - Минимизировать логику внутри сервлета, вынося её в сервисные классы для поддержки читаемости и тестируемости.
Фильтры (Filter) позволяют выполнять предварительную обработку запросов и пост-обработку ответов без изменения сервлета, обеспечивая единообразное логирование, аутентификацию и управление кодировкой.
Корректная маршрутизация и работа с HTTP-запросами напрямую влияют на производительность приложения и безопасность, поэтому важно строго разграничивать обработку GET и POST, проверять все входные данные и возвращать корректные коды состояния HTTP.
Взаимодействие с базой данных через JDBC и ORM
JDBC (Java Database Connectivity) предоставляет прямой доступ к базам данных через драйверы, поддерживающие SQL. Для подключения требуется указать URL базы, имя пользователя и пароль. Использование `PreparedStatement` вместо `Statement` снижает риск SQL-инъекций и повышает производительность при повторных запросах.
Реализация транзакций через JDBC осуществляется с помощью методов `setAutoCommit(false)` и `commit()`. Для отката используется `rollback()`. При работе с большими объемами данных рекомендуется применять пакетную обработку (`addBatch()` и `executeBatch()`), что уменьшает сетевую нагрузку и ускоряет выполнение.
ORM (Object-Relational Mapping) позволяет работать с объектами Java вместо прямого написания SQL. Популярные фреймворки – Hibernate и EclipseLink. ORM автоматизирует генерацию SQL, управление транзакциями и кэширование, снижая вероятность ошибок маппинга.
При использовании ORM важно корректно определять связи между сущностями: `@OneToMany`, `@ManyToOne`, `@ManyToMany`. Для оптимизации запросов применяется жадная (`fetch = FetchType.EAGER`) и ленивaя (`fetch = FetchType.LAZY`) загрузка, в зависимости от сценария. Неправильная стратегия загрузки может вызвать «N+1 Select Problem».
Для повышения производительности ORM рекомендуется: использовать вторичный кэш, ограничивать выборку полей через `select new` или DTO, минимизировать количество транзакций и применять индексы на часто фильтруемых колонках.
Интеграция JDBC и ORM возможна: Hibernate поддерживает нативные SQL-запросы через `createNativeQuery()`, что позволяет сохранять критически оптимизированные запросы без отказа от преимуществ ORM.
При проектировании веб-приложения на Java важно стандартизировать слой доступа к данным через DAO или Repository, что упрощает тестирование и замену конкретной реализации базы данных без изменения бизнес-логики.
Управление сессиями и хранение пользовательских данных

В веб-приложениях на Java управление сессиями реализуется через объект HttpSession, доступный в сервлетах и Spring-контроллерах. Каждая сессия идентифицируется уникальным sessionId, который передается клиенту в виде cookie или URL-параметра. Для повышения безопасности рекомендуется устанавливать атрибут HttpOnly для cookie и использовать Secure при работе через HTTPS.
Создание сессии осуществляется вызовом request.getSession(true). Для хранения пользовательских данных допустимо использовать примитивные типы, объекты Java или коллекции, но важно ограничивать размер сессии, чтобы избежать переполнения памяти сервера. Рекомендуется хранить только идентификаторы и ключевые данные, а объемные объекты сохранять в базе данных.
Для управления временем жизни сессии используется метод session.setMaxInactiveInterval(), задающий период неактивности до автоматического завершения. При критически важных приложениях целесообразно реализовать механизмы явного завершения сессии через session.invalidate() после выхода пользователя или завершения транзакций.
Хранение пользовательских данных вне сессии рекомендуется реализовывать через базы данных или кэш-системы (Redis, Memcached) с привязкой к идентификатору сессии. Это позволяет масштабировать приложение горизонтально без потери состояния и минимизирует риски утечек при перезапуске сервера.
Для защиты данных в сессии следует применять шифрование и контроль целостности при хранении чувствительных данных. Например, хранение паролей допускается только в виде хэшей с солью, а токены аутентификации – с использованием JWT с подписью и сроком действия.
При высоких нагрузках рекомендуется использовать механизмы распределенных сессий с синхронизацией через кластер или базы данных, чтобы обеспечить доступность и консистентность данных между узлами приложения.
Использование шаблонов JSP и генерация динамических страниц
JSP (JavaServer Pages) позволяет создавать динамические HTML-страницы, объединяя статический HTML с Java-кодом. Основная цель JSP – отделение логики отображения от бизнес-логики. Для этого используют теги JSP, скриплеты и выражения EL (Expression Language).
Шаблоны JSP обычно включают общий каркас страницы: шапку, навигацию, футер и подключаемые CSS/JS. Использование директивы <%@ include file="header.jsp" %> позволяет повторно применять код на нескольких страницах без дублирования. Для более гибкой структуры применяют теги JSTL и собственные кастомные теги.
Динамический контент в JSP формируется с помощью сервлетов или бинов. Например, сервлет получает данные из базы, помещает их в объект request или session, а JSP-шаблон отображает их через EL: ${user.name}. Такой подход повышает читаемость кода и упрощает поддержку.
Для предотвращения смешивания логики и разметки рекомендуется использовать MVC-подход: сервлеты обрабатывают запросы и формируют модель, JSP отвечает исключительно за отображение. Использование тегов JSTL, например <c:forEach> для циклов и <c:if> для условий, позволяет полностью исключить Java-код из разметки.
Оптимизация загрузки страниц достигается через кэширование частично статического контента и использование include или jsp:include для динамических фрагментов. JSP-компилятор автоматически преобразует страницы в сервлеты, что обеспечивает высокую производительность при многократных запросах.
Рекомендуется хранить все шаблоны в отдельной папке, например /WEB-INF/jsp/, чтобы исключить прямой доступ через URL. При этом структура проекта должна позволять быстро подключать общие элементы и обеспечивать повторное использование компонентов.
Для сложных проектов целесообразно комбинировать JSP с современными фреймворками, такими как Spring MVC, чтобы централизованно управлять маршрутизацией и безопасностью, оставляя JSP исключительно для формирования HTML на основе модели данных.
Обработка ошибок и логирование действий приложения

В Java веб-приложениях ошибки обрабатываются через блоки try-catch и глобальные обработчики, например, @ControllerAdvice в Spring. Исключения разделяют на проверяемые (checked) и непроверяемые (unchecked) для корректного контроля потока и формирования ответа клиенту.
Логирование выполняется через SLF4J с Logback или Log4j2. Действия с изменением состояния приложения логируются на уровне INFO, диагностические сообщения – DEBUG, критические ошибки – ERROR. Для каждого события указываются timestamp, уровень, класс, метод и уникальный requestId.
Логи REST API должны включать идентификаторы сессии и пользователя. Чувствительные данные необходимо маскировать. Стек вызовов исключений всегда фиксируется для быстрого выявления причины сбоя. Игнорирование ошибок без логирования недопустимо.
Для централизованной обработки создаются сервисы ошибок, которые преобразуют исключения в структурированные ответы клиенту и одновременно отправляют запись в лог. Логи рекомендуется хранить в JSON с полями timestamp, level, class, message, requestId для удобного анализа.
Интеграция с ELK Stack или Prometheus/Grafana позволяет собирать, фильтровать и визуализировать логи, анализировать узкие места и регрессии. Логи группируют по типу ошибки, URL или пользователю для быстрого реагирования на сбои.
Интеграция внешних API и обмен данными в формате JSON

Для интеграции внешних API в Java-приложение рекомендуется использовать библиотеки типа `HttpClient` (Java 11+) или `OkHttp`. Запрос к API формируется с указанием метода (`GET`, `POST`), заголовков и тела запроса, если это требуется. Важно учитывать таймауты подключения и чтения для предотвращения зависаний приложения.
Ответ от API обычно приходит в формате JSON. Для его обработки оптимально применять библиотеки `Jackson` или `Gson`, которые позволяют преобразовать JSON в Java-объекты и обратно. Рекомендуется использовать строгую типизацию моделей данных и аннотации `@JsonProperty` для сопоставления имен полей.
При проектировании обмена данными следует учитывать структуру JSON. Например, для вложенных объектов и массивов лучше заранее создавать соответствующие вложенные классы, чтобы избежать ошибок десериализации.
| Рекомендация | Описание |
|---|---|
| Повторная попытка запроса | Использовать стратегию повторных попыток с экспоненциальной задержкой при временных сбоях API. |
| Обработка ошибок | Парсить код ответа HTTP и логировать ошибки API для последующего анализа. |
| Валидация JSON | Проверять корректность формата перед десериализацией, используя схемы JSON Schema или встроенные механизмы библиотек. |
| Кэширование | Сохранять часто используемые ответы API в памяти или внешнем кэше для снижения числа вызовов. |
| Безопасность | Шифровать и защищать ключи API, использовать HTTPS и токены с ограниченными правами доступа. |
Для передачи данных на внешние сервисы в формате JSON важно сериализовать объекты через `ObjectMapper` (Jackson) или `Gson.toJson()`, контролируя поля, которые должны быть включены, чтобы не передавать лишние данные. Использование DTO (Data Transfer Objects) снижает связность между слоями приложения и упрощает тестирование.
В сценариях с большим объёмом данных рекомендуется применять потоковую обработку JSON (`Streaming API`) для уменьшения потребления памяти и ускорения передачи данных.
Вопрос-ответ:
Какая роль сервлетов в Java веб-приложении?
Сервлеты являются компонентами, которые обрабатывают запросы пользователей и формируют ответы. Они работают на сервере и получают данные от клиента через HTTP-запросы. Например, когда пользователь заполняет форму на сайте, сервлет получает эти данные, обрабатывает их, может взаимодействовать с базой данных и возвращает результат в виде веб-страницы или JSON.
Как взаимодействуют веб-приложения на Java с базой данных?
Для работы с базой данных обычно используют JDBC или фреймворки типа Hibernate. Приложение формирует запрос к базе, отправляет его и получает данные. Эти данные затем обрабатываются на сервере и передаются пользователю. Важная часть — управление соединениями с базой, чтобы сервер мог обслуживать большое количество запросов без задержек.
Почему используют MVC-подход в веб-приложениях на Java?
MVC разделяет структуру приложения на три слоя: модель, представление и контроллер. Модель хранит данные и бизнес-логику, представление отвечает за отображение информации пользователю, а контроллер управляет взаимодействием между ними. Такой подход упрощает поддержку кода, позволяет работать над разными слоями параллельно и снижает вероятность ошибок при изменениях интерфейса или логики.
Каким образом Java-приложение обрабатывает многопользовательские запросы одновременно?
Веб-сервер создаёт отдельный поток для каждого входящего запроса. Потоки работают параллельно, что позволяет обслуживать несколько пользователей одновременно. Сервлеты должны быть написаны так, чтобы не возникало конфликтов при одновременном доступе к общим данным. Для этого используют синхронизацию или структуры данных, поддерживающие многопоточность.
Что такое сессии в Java веб-приложении и зачем они нужны?
Сессия позволяет хранить информацию о конкретном пользователе между запросами. Например, данные о корзине покупок или настройках интерфейса. Сессия создаётся сервером и связывается с пользователем через идентификатор, который хранится в cookie или URL. Это помогает поддерживать состояние приложения и делать взаимодействие с пользователем более удобным.
Каким образом Java управляет обработкой запросов пользователей в веб-приложении?
Веб-приложение на Java обычно использует архитектуру клиент-сервер. Когда пользователь отправляет запрос через браузер, он достигает сервера, где запускается специальный компонент, называемый сервлетом. Сервлет получает информацию о запросе, анализирует её и передает данные в бизнес-логику приложения. После обработки сервлет формирует ответ, который возвращается пользователю в виде HTML, JSON или другого формата. Такая схема позволяет разделять обработку данных и взаимодействие с пользователем, поддерживая структуру приложения чистой и удобной для расширения.
Почему важна организация многослойной архитектуры в веб-приложении на Java?
Многослойная архитектура разделяет приложение на отдельные уровни: презентационный слой, слой бизнес-логики и слой работы с данными. Это позволяет изменять один уровень без необходимости перерабатывать остальные. Например, интерфейс пользователя может обновляться без вмешательства в логику обработки данных. Такой подход снижает вероятность ошибок и упрощает сопровождение приложения, поскольку каждый слой выполняет конкретные задачи и взаимодействует с другими слоями через четко определённые интерфейсы.