Работа с библиотекой pandas начинается с понимания структуры DataFrame. Каждый столбец представляет собой объект Series, который можно создавать и модифицировать напрямую. Добавление нового столбца не требует копирования всего DataFrame и выполняется за константное время по ссылке на существующие данные.
Самый простой способ добавить столбец – присвоить ему значение через синтаксис df[‘новый_столбец’] = значения. Значения могут быть скалярными, списками той же длины, либо объектами Series с совпадающими индексами. При этом pandas автоматически выровняет данные по индексам, предотвращая смещение строк.
Для вычисляемых столбцов рекомендуется использовать методы apply или векторизованные операции. Они работают быстрее циклов и позволяют выполнять сложные преобразования на уровне столбцов без использования внешних библиотек. Например, создание столбца с результатами арифметических операций между существующими столбцами выполняется одной строкой.
Если необходимо добавлять столбцы по условию, удобно использовать numpy.where или метод loc. Это позволяет задавать правила добавления значений без промежуточных шагов, сохраняя DataFrame компактным и читаемым. Такая практика особенно эффективна при работе с большими наборами данных.
Создание нового столбца с константным значением
Чтобы добавить в DataFrame столбец с одинаковым значением для всех строк, используется прямое присваивание через имя нового столбца. Например, при наличии DataFrame df с пятью строками можно создать столбец ‘Статус’ со значением ‘Активный’:
df['Статус'] = 'Активный'
Если требуется числовое значение, синтаксис аналогичен. Для столбца ‘Баллы’ с константой 100:
df['Баллы'] = 100
При больших DataFrame этот метод сохраняет высокую производительность, так как не требует циклов и функций apply. Все элементы нового столбца автоматически повторяют заданное значение, а тип данных определяется по типу присвоенной константы.
Для создания нескольких константных столбцов одновременно можно использовать метод assign, который возвращает новый DataFrame:
df = df.assign(Статус='Активный', Баллы=100)
Этот подход полезен при построении шаблонов DataFrame, где необходимо сразу определить несколько фиксированных атрибутов для каждой записи.
Добавление столбца на основе существующих данных
В Pandas часто требуется создать новый столбец, используя значения уже существующих. Это позволяет автоматизировать вычисления и объединять информацию внутри DataFrame.
Примеры способов добавления столбца:
- Через простые арифметические операции:
import pandas as pd
df = pd.DataFrame({
'Цена': [100, 150, 200],
'Количество': [2, 3, 1]
})
df['Сумма'] = df['Цена'] * df['Количество']
print(df)- С помощью условий с
np.where:
import numpy as np
df['Скидка'] = np.where(df['Сумма'] > 200, 0.1, 0)
print(df)- Использование метода
applyдля сложных вычислений:
df['Категория'] = df['Сумма'].apply(lambda x: 'Высокая' if x > 200 else 'Низкая')
print(df)Рекомендации при добавлении столбцов на основе других:
- Использовать векторные операции вместо циклов для повышения производительности.
- Проверять типы данных исходных столбцов перед вычислениями.
- Избегать модификации DataFrame внутри
apply, чтобы сохранить чистоту кода. - При необходимости создавать копию DataFrame, чтобы избежать нежелательных изменений исходных данных.
Использование функции для генерации значений столбца
В Pandas для создания нового столбца на основе вычислений с существующими данными удобно использовать метод apply() с пользовательской функцией. Например, если есть DataFrame df с колонкой 'цена', можно добавить столбец с НДС:
df['цена_с_ндс'] = df['цена'].apply(lambda x: x * 1.2)
Для более сложных вычислений создайте отдельную функцию. Если необходимо учитывать несколько колонок, используйте параметр axis=1:
def категория(row):
if row['цена'] < 100: return 'низкая'
elif row['цена'] < 500: return 'средняя'
else: return 'высокая'
df['категория'] = df.apply(категория, axis=1)
Методы apply() и пользовательские функции позволяют выполнять векторизованные операции и сохранять читаемость кода. Для генерации случайных значений столбца можно использовать библиотеку numpy:
import numpy as np
df['случайное_число'] = np.random.randint(0, 100, size=len(df))
Важно избегать повторного вызова функций внутри цикла по DataFrame, чтобы не ухудшать производительность. Функции должны быть чистыми, без побочных эффектов, что обеспечивает корректное применение к каждой строке или элементу.
Добавление столбца с помощью условий и логики
В pandas создание нового столбца на основе условий позволяет динамически формировать данные без ручного редактирования. Основные подходы включают использование функции apply, логических операций и метода np.where.
Пример с apply и пользовательской функцией:
import pandas as pd
data = {'Возраст': [16, 25, 40, 15, 30]}
df = pd.DataFrame(data)
def категория_возраста(age):
if age < 18:
return 'Несовершеннолетний'
elif age <= 30:
return 'Молодой взрослый'
else:
return 'Взрослый'
df['Категория'] = df['Возраст'].apply(категория_возраста)
При работе с большими DataFrame эффективнее использовать np.where или логические выражения:
import numpy as np
df['Скидка'] = np.where(df['Возраст'] < 18, 0.1, 0.05)
Можно комбинировать несколько условий через логические операторы:
df['Группа'] = np.where(df['Возраст'] < 18, 'Молодежь',
np.where(df['Возраст'] < 60, 'Взрослые', 'Пожилые'))
Использование логики с loc позволяет обновлять столбцы выборочно:
df['Статус'] = 'Активный'
df.loc[df['Возраст'] >= 60, 'Статус'] = 'Пенсионер'
- Для сложных условий объединяйте <code>np.select</code> с списком критериев и значений.
- Логические операторы
&и|требуют скобок для правильной приоритизации. - Используйте методы
applyиlambdaдля нестандартной логики, когда стандартные функцииnp.whereнедостаточны.
Правильное применение условий повышает читаемость кода и снижает вероятность ошибок при массовой обработке данных.
Вставка столбца в конкретную позицию DataFrame
Для добавления нового столбца в определённое место DataFrame используется метод insert(). Его синтаксис: DataFrame.insert(loc, column, value, allow_duplicates=False), где loc – индекс позиции, column – имя столбца, value – данные для столбца, а allow_duplicates запрещает повторение имен.
Пример добавления столбца с оценками студентов на третью позицию:
import pandas as pd
data = {'Имя': ['Анна', 'Иван', 'Олег'],
'Возраст': [20, 22, 21]}
df = pd.DataFrame(data)
df.insert(2, 'Оценка', [5, 4, 5])
print(df)
Результат:
| Имя | Возраст | Оценка |
|---|---|---|
| Анна | 20 | 5 |
| Иван | 22 | 4 |
| Олег | 21 | 5 |
Если loc превышает количество столбцов, столбец добавляется в конец. Для динамического определения позиции можно использовать df.columns.get_loc('Возраст') + 1 вместо числового индекса.
Метод insert() эффективен для больших DataFrame, так как изменяет структуру на месте без создания копии. Для добавления нескольких столбцов одновременно используют комбинированные вызовы insert() или пересоздание DataFrame через pd.concat().
Объединение нескольких Series в новый столбец
Для объединения нескольких Series в один столбец DataFrame используют метод pd.concat или присваивание через оператор =. Например, если есть Series s1 и s2 с одинаковой длиной, можно создать новый столбец так:
df['новый_столбец'] = s1 + s2 – значения суммируются по индексам. Если требуется объединение строк, используют .astype(str) и конкатенацию через +:
df['объединённый_столбец'] = s1.astype(str) + '_' + s2.astype(str)
Для большего числа Series применяется pd.concat([s1, s2, s3], axis=1), после чего столбцы можно объединить функцией agg:
df['объединённый'] = df[['s1','s2','s3']].agg('-'.join, axis=1). Это формирует единый строковый столбец с разделителем -. Для чисел используют sum вместо '-'.join.
При объединении Series разной длины рекомендуется сначала привести их к одинаковому индексу с помощью reindex или fillna, иначе появятся NaN. Например:
s2 = s2.reindex(s1.index, fill_value=0)
Для динамического объединения произвольного числа Series можно использовать генератор списка и reduce из functools:
from functools import reduce
df['total'] = reduce(lambda x, y: x + y, list_of_series)
Такой подход минимизирует ошибки индексации и упрощает добавление нового столбца в существующий DataFrame без ручного перечисления всех Series. Объединение строковых и числовых Series требует приведения типов для корректного сложения или конкатенации.
Добавление столбца с пропущенными значениями и заполнение позже
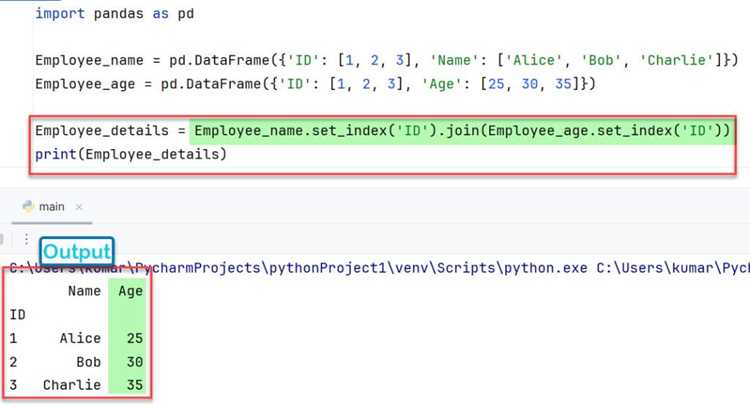
В pandas добавить столбец с пустыми значениями можно с помощью значения `None` или `numpy.nan`. Это создаёт колонку, готовую к последующему заполнению. Например:
import pandas as pd
import numpy as np
df = pd.DataFrame({'Имя': ['Анна', 'Борис', 'Виктор']})
df['Возраст'] = np.nan
В результате создаётся столбец `Возраст` с тремя `NaN`. Такой подход полезен, когда данные будут поступать поэтапно или из разных источников.
Для заполнения пропусков можно использовать конкретные значения, расчётные данные или метод заполнения по соседним строкам. Примеры:
# Заполнение фиксированным числом
df['Возраст'].fillna(30, inplace=True)
# Заполнение медианой существующих значений
df['Возраст'].fillna(df['Возраст'].median(), inplace=True)
# Заполнение методом вперёд
df['Возраст'].fillna(method='ffill', inplace=True)
Если предполагается регулярное добавление данных, рекомендуется создавать столбец сразу с `NaN`, чтобы сохранить целостность индексов и упростить последующую обработку. Использование `astype()` позволяет сразу задать тип данных для нового столбца:
df['Возраст'] = pd.Series([np.nan]*len(df), dtype='float')
Это предотвращает автоматическое приведение типов и упрощает работу с числовыми расчётами, например, суммированием или средним значением после заполнения пропусков.
Проверка и обновление существующего столбца
Перед изменением столбца убедитесь, что он существует в DataFrame. Для этого используйте `if ‘название_столбца’ in df.columns:`. Этот метод предотвращает ошибки KeyError при попытке обращения к несуществующему столбцу.
Для обновления значений столбца применяйте векторизированные операции. Например, `df[‘столбец’] = df[‘столбец’] * 2` увеличит все числовые значения вдвое без необходимости использовать циклы. Такой подход эффективнее и сокращает время выполнения для больших DataFrame.
Если требуется обновление на основе условия, используйте `loc`. Например, `df.loc[df[‘столбец’] > 10, ‘столбец’] = 10` ограничит максимальные значения столбца 10. Это безопаснее, чем применять `apply` с функцией, так как `loc` работает напрямую с индексами и сохраняет тип данных.
Для замены столбца новыми данными длина новой серии должна совпадать с количеством строк DataFrame: `df[‘столбец’] = pd.Series(новые_данные)`. Несоответствие длины вызовет ValueError.
При необходимости объединять данные с другим источником используйте `map` или `replace`. Например, `df[‘столбец’] = df[‘столбец’].map({‘A’: 1, ‘B’: 2})` преобразует категориальные значения в числовые без изменения структуры DataFrame.
После обновления столбца рекомендуется проверить тип данных `df.dtypes[‘столбец’]` и корректность значений через `df[‘столбец’].unique()` или `df[‘столбец’].describe()`. Это помогает избежать логических ошибок в последующих вычислениях.
Вопрос-ответ:
Какие способы существуют для добавления нового столбца в DataFrame?
В Python с использованием библиотеки pandas можно добавить столбец разными способами. Самый простой метод — присвоить значения через оператор присваивания: df[‘новый_столбец’] = список_значений или серия pandas. Также можно использовать метод assign(), который возвращает новый DataFrame с добавленным столбцом: df = df.assign(новый_столбец=значения). Еще один вариант — использовать insert(), который позволяет указать точное место вставки столбца: df.insert(индекс_позиции, ‘название_столбца’, значения).
Что произойдет, если длина списка значений не совпадает с числом строк DataFrame?
Если при добавлении столбца через присвоение длина списка или массива отличается от количества строк в DataFrame, pandas выдаст ошибку ValueError с сообщением о несовпадении размеров. Это связано с тем, что каждая строка DataFrame должна получить значение в новом столбце. Чтобы избежать ошибки, нужно либо использовать значения подходящей длины, либо задать одно значение, которое будет автоматически распространено на все строки.
Можно ли добавить столбец, используя существующие данные из других столбцов?
Да, в pandas часто добавляют новые столбцы на основе вычислений с другими столбцами. Например, можно создать столбец с суммой двух существующих: df[‘сумма’] = df[‘столбец1’] + df[‘столбец2’]. Также возможны более сложные операции через функцию apply(): df[‘новый’] = df.apply(lambda row: row[‘столбец1’] * 2 if row[‘столбец2’] > 5 else 0, axis=1), где значение зависит от условий, заданных для каждой строки.
Какая разница между методами assign() и insert() при добавлении столбца?
Метод assign() создает новый DataFrame и добавляет столбец в конце, не изменяя оригинальный DataFrame, если не присвоить результат обратно. Метод insert() изменяет существующий DataFrame на месте и позволяет указать позицию столбца, а не только добавлять в конец. То есть insert() удобен, если нужно контролировать порядок столбцов, а assign() лучше использовать для цепочек операций без изменения исходного объекта.
Можно ли добавлять столбец с помощью словаря?
Да, при добавлении столбца в DataFrame допустимо использовать словарь, где ключи соответствуют индексам строк, а значения — содержимому нового столбца. Например: df[‘новый’] = {0: ‘a’, 2: ‘b’}. В этом случае pandas автоматически сопоставит ключи с индексами DataFrame, а для строк, которых нет в словаре, будет установлено значение NaN.
Как добавить новый столбец в DataFrame с одинаковыми значениями для всех строк?
Для этого можно просто присвоить значение новому столбцу через имя столбца. Например, если есть DataFrame df и нужно добавить столбец «Статус» со значением «Активен» для всех строк, используется запись: df[‘Статус’] = ‘Активен’. Все строки получат указанное значение автоматически. Такой способ удобен, если значение одно для каждой записи, и не требуется вычислять его динамически.
Можно ли добавить столбец на основе значений других столбцов в DataFrame?
Да, можно создавать новые столбцы на основе существующих данных. Например, если в DataFrame есть столбцы «Цена» и «Количество», можно добавить столбец «Сумма» так: df[‘Сумма’] = df[‘Цена’] * df[‘Количество’]. В результате каждая строка получит значение, вычисленное по соответствующим ячейкам. Такой подход удобен для расчетов и аналитики прямо внутри DataFrame без необходимости использовать отдельные переменные или циклы.