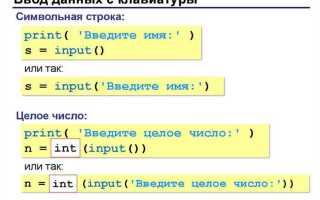
Python предоставляет несколько библиотек для работы с Excel, включая pandas и openpyxl. Pandas позволяет сохранять таблицы напрямую из DataFrame в формат .xlsx с помощью метода to_excel(), при этом поддерживаются параметры для указания имени листа, формата данных и включения или исключения индекса.
Для простого экспорта достаточно создать DataFrame, например: df = pd.DataFrame({‘Имя’: [‘Алексей’,’Мария’], ‘Возраст’:[28,34]}), затем использовать df.to_excel(‘output.xlsx’, index=False). Index=False исключает автоматический индекс pandas, что упрощает работу с данными в Excel.
Если требуется форматирование, стилизация ячеек или добавление формул, стоит подключать openpyxl. Она позволяет изменять ширину колонок, применять условное форматирование и добавлять формулы без потери данных при сохранении файла.
Для больших наборов данных рекомендуется использовать xlsxwriter, который оптимизирован для записи объемных таблиц с минимальным потреблением памяти. С его помощью можно создавать несколько листов в одном файле и управлять форматированием чисел, дат и текста.
Практика показывает, что комбинация pandas для подготовки данных и openpyxl или xlsxwriter для сохранения с настройками формата обеспечивает максимальную гибкость и контроль над конечным файлом Excel.
Экспорт данных из Python в Excel: пошаговое руководство

Для начала убедитесь, что установлен пакет pandas и библиотека openpyxl, используемая для записи файлов Excel. Установку можно выполнить командой: pip install pandas openpyxl.
Создайте DataFrame с данными, которые необходимо экспортировать. Пример:
import pandas as pd
data = {'Имя': ['Анна', 'Иван', 'Мария'], 'Возраст': [28, 34, 22], 'Город': ['Москва', 'Санкт-Петербург', 'Казань']}
df = pd.DataFrame(data)
Для экспорта данных используйте метод to_excel(). Укажите путь к файлу и параметр index=False, если не требуется сохранять индекс DataFrame:
df.to_excel('данные.xlsx', index=False, engine='openpyxl')
Если необходимо экспортировать несколько листов в одном файле, используйте ExcelWriter:
with pd.ExcelWriter('много_листов.xlsx', engine='openpyxl') as writer:
df.to_excel(writer, sheet_name='Лист1', index=False)
df.to_excel(writer, sheet_name='Лист2', index=False)
Для сохранения стиля ячеек или форматов чисел можно использовать библиотеку openpyxl напрямую. Например, установка формата даты:
from openpyxl import load_workbook
wb = load_workbook('данные.xlsx')
ws = wb.active
for cell in ws['B']:
cell.number_format = 'DD.MM.YYYY'
wb.save('данные.xlsx')
Для больших объемов данных рекомендуется использовать параметр chunksize при записи DataFrame, чтобы снизить нагрузку на память:
for chunk in pd.read_csv('большой_файл.csv', chunksize=10000):
chunk.to_excel('результат.xlsx', index=False, engine='openpyxl', mode='a')
Контролируя параметры экспорта и используя возможности pandas и openpyxl, можно эффективно создавать Excel-файлы с любым объемом данных и различными форматами ячеек.
Установка и настройка библиотеки openpyxl для работы с Excel
Для работы с Excel в Python чаще всего используют библиотеку openpyxl. Установка выполняется через pip:
pip install openpyxl
После установки рекомендуется проверить версию для исключения несовместимости:
python -m pip show openpyxl
Создание и чтение файлов Excel выполняется через объекты Workbook и load_workbook. Пример базовой настройки рабочей книги:
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.title = "Данные"
wb.save("example.xlsx")
Для открытия существующего файла используется:
from openpyxl import load_workbook
wb = load_workbook("example.xlsx")
ws = wb.active
Рекомендуется заранее определить кодировку и формат ячеек, особенно при работе с не-ASCII символами и датами. Для удобства работы с таблицами можно использовать следующий справочный шаблон:
| Метод / Атрибут | Описание | Пример |
|---|---|---|
| Workbook() | Создание новой рабочей книги | wb = Workbook() |
| load_workbook(filename) | Открытие существующего файла | wb = load_workbook(«data.xlsx») |
| wb.active | Получение активного листа | ws = wb.active |
| ws.title | Изменение имени листа | ws.title = «Отчёт» |
| wb.save(filename) | Сохранение книги на диск | wb.save(«output.xlsx») |
Для ускорения работы с большими таблицами рекомендуется включить режим read_only=True при загрузке файлов, если нет необходимости редактировать содержимое. Это снижает нагрузку на память и увеличивает скорость обработки.
Создание нового Excel-файла и добавление листов из Python
Для работы с Excel в Python удобно использовать библиотеку openpyxl. Она позволяет создавать файлы, управлять листами и записывать данные напрямую.
Создание нового файла и добавление листов выполняется следующим образом:
- Импортируем класс
Workbookизopenpyxl:from openpyxl import Workbook - Создаем новый объект рабочей книги:
wb = Workbook() - По умолчанию создается один лист с именем
Sheet. Его можно переименовать:ws = wb.active ws.title = "Данные" - Для добавления дополнительных листов используем метод
create_sheet:wb.create_sheet(title="Отчеты") wb.create_sheet(title="Статистика") - Сохраняем рабочую книгу в файл Excel:
wb.save("новый_файл.xlsx")
Дополнительные рекомендации:
- Аргумент
indexметодаcreate_sheetпозволяет задать позицию нового листа. - Для массового создания листов удобно использовать цикл и список имен:
for name in ["Январь", "Февраль", "Март"]:
wb.create_sheet(title=name)wb.remove(sheet) или del wb[sheet_name].Эта последовательность позволяет создавать структуру Excel-файла, управлять количеством и именами листов, готовя файл к записи данных из Python.
Запись данных из списка и словаря в ячейки Excel
Для записи данных из Python в Excel используется библиотека openpyxl. Начнем с списка. Предположим, у нас есть список чисел: data_list = [10, 20, 30, 40]. Создаем книгу и лист, затем последовательно записываем элементы списка в столбец A:
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
for i, value in enumerate(data_list, start=1):
ws[f"A{i}"] = value
wb.save("list_data.xlsx")
Для словаря структура записи отличается. Пусть data_dict = {«Имя»: «Иван», «Возраст»: 30, «Город»: «Москва»}. Ключи можно записать в строку заголовков, а значения в следующую строку:
data_dict = {"Имя": "Иван", "Возраст": 30, "Город": "Москва"}
for col, key in enumerate(data_dict.keys(), start=1):
ws.cell(row=1, column=col, value=key)
ws.cell(row=2, column=col, value=data_dict[key])
wb.save("dict_data.xlsx")
При работе с несколькими строками словарей удобно использовать цикл. Например, для списка словарей records = [{«Имя»: «Иван», «Возраст»: 30}, {«Имя»: «Ольга», «Возраст»: 25}] заголовки формируются из ключей первого словаря, а значения вставляются построчно:
headers = records[0].keys()
for col, key in enumerate(headers, start=1):
ws.cell(row=1, column=col, value=key)
for row, record in enumerate(records, start=2):
for col, key in enumerate(headers, start=1):
ws.cell(row=row, column=col, value=record[key])
wb.save("records_data.xlsx")
Таким образом, списки записываются последовательно в строки или столбцы, а словари и их наборы удобно представлять в виде таблиц с заголовками. Рекомендуется заранее определять порядок ключей для сохранения структуры и читаемости Excel-файла.
Экспорт DataFrame из pandas в Excel с сохранением индексов и заголовков
Для экспорта DataFrame из pandas в Excel используется метод to_excel(). Он позволяет сохранить как данные, так и индексы и заголовки столбцов без дополнительной обработки.
Пример базового экспорта:
import pandas as pd
df = pd.DataFrame({'Имя': ['Анна', 'Борис'], 'Возраст': [25, 30]})
df.to_excel('данные.xlsx', index=True, header=True)
Параметр index=True гарантирует сохранение индексов строк. header=True сохраняет названия столбцов. Если не указать эти параметры, по умолчанию индексы сохраняются, а заголовки также экспортируются, но явное указание улучшает читаемость кода.
Для экспорта на определенный лист Excel применяется аргумент sheet_name:
df.to_excel('данные.xlsx', sheet_name='Сотрудники', index=True, header=True)
При работе с большими файлами или при необходимости многократного добавления листов используется ExcelWriter:
with pd.ExcelWriter('данные.xlsx', engine='xlsxwriter') as writer:
df.to_excel(writer, sheet_name='Сотрудники', index=True, header=True)
Такой подход обеспечивает контроль над форматированием, позволяет добавлять несколько листов и гарантирует точное сохранение структуры DataFrame, включая индексы и заголовки столбцов.
Форматирование ячеек и столбцов при экспорте данных
Для точного представления данных в Excel после экспорта из Python важно контролировать формат ячеек и ширину столбцов. Библиотека openpyxl предоставляет гибкие инструменты для этих задач.
Примеры форматирования:
- Ширина столбца: с помощью
worksheet.column_dimensions['A'].width = 20можно установить ширину столбца A в 20 единиц. - Формат чисел: для отображения чисел с двумя знаками после запятой:
cell.number_format = '0.00'. - Формат даты: для даты в формате день.месяц.год:
cell.number_format = 'DD.MM.YYYY'. - Выравнивание текста: горизонтальное и вертикальное выравнивание задается через
Alignment(horizontal='center', vertical='center'). - Жирный текст и цвет:
Font(bold=True, color='FF0000')для выделения заголовков или важных значений. - Объединение ячеек:
worksheet.merge_cells('A1:C1')позволяет объединить диапазон ячеек. - Автоширина столбцов: расчет ширины по длине контента:
for col in worksheet.columns: max_length = max(len(str(cell.value)) for cell in col) worksheet.column_dimensions[col[0].column_letter].width = max_length + 2
Совмещая эти методы, можно экспортировать данные в Excel с четкой структурой, читаемыми заголовками и корректным отображением числовых и датированных значений.
Добавление графиков и формул в Excel через Python
Для создания графиков в Excel из Python удобно использовать библиотеку openpyxl. После записи данных в лист можно добавить диаграмму с помощью класса openpyxl.chart. Например, чтобы построить линейный график по диапазону A1:A10 и B1:B10:
from openpyxl import Workbook
from openpyxl.chart import LineChart, Reference
wb = Workbook()
ws = wb.active
# заполнение данных
chart = LineChart()
data = Reference(ws, min_col=2, min_row=1, max_row=10)
chart.add_data(data, titles_from_data=True)
ws.add_chart(chart, "D5")
wb.save("example.xlsx")
Для добавления формул используйте синтаксис Excel в виде строки, присваивая её ячейке. Например, для суммы значений в диапазоне B1:B10:
ws["B11"] = "=SUM(B1:B10)"
Можно комбинировать функции: вычислять среднее =AVERAGE(B1:B10), искать максимум =MAX(B1:B10) или использовать условные формулы =IF(B1>100, \"Да\", \"Нет\"). openpyxl автоматически обновляет формулы при открытии файла в Excel.
Для сложных графиков, например комбинированных или с вторичной осью, создайте несколько объектов Chart и укажите их axId и grouping. Это позволяет визуализировать данные с разными масштабами и типами диаграмм.
При работе с большими массивами данных рекомендуется добавлять формулы и диаграммы после заполнения всех значений, чтобы избежать лишних пересчётов и ускорить сохранение файла.
Сохранение и проверка готового Excel-файла после экспорта
Следующий этап – проверка целостности данных. Откройте файл в Excel и проверьте соответствие количества строк и столбцов исходному DataFrame. Обратите внимание на форматирование чисел и дат: Python может экспортировать даты в формате datetime, который Excel интерпретирует по-своему. Для сохранения формата используйте аргумент date_format='YYYY-MM-DD' в pandas или настройку number_format в openpyxl.
Проверка заголовков столбцов обязательна: убедитесь, что названия совпадают с исходными, без обрезки символов или изменения регистра. При необходимости примените sheet.cell(row=1, column=i).value для контроля имен.
Также следует проверить наличие пустых ячеек и правильность формул. Если в DataFrame присутствовали формулы, они должны быть экспортированы как значения, так как pandas не поддерживает формулы Excel напрямую. Для openpyxl формулы можно вставлять через cell.value = '=SUM(A2:A10)'.
Наконец, протестируйте открытие файла на другом устройстве или в другой версии Excel, чтобы убедиться, что структура таблицы и форматирование сохраняются. Для больших таблиц рекомендуется дополнительно выполнить проверку через df_read = pd.read_excel('путь_к_файлу.xlsx'), чтобы сравнить данные с исходным DataFrame и исключить потерю информации.
Вопрос-ответ:
Какие библиотеки Python лучше использовать для записи данных в Excel?
Для записи данных в Excel чаще всего применяются библиотеки pandas и openpyxl. Pandas позволяет быстро конвертировать DataFrame в Excel-файл через метод to_excel(), а openpyxl даёт больше контроля над форматированием, стилями и структурой таблицы. Можно комбинировать обе библиотеки: pandas для экспорта, openpyxl для тонкой настройки внешнего вида.
Можно ли экспортировать в Excel сразу несколько листов из одного скрипта Python?
Да, это возможно с помощью pandas и ExcelWriter. Нужно создать объект ExcelWriter и указывать разные имена листов при сохранении разных DataFrame. Например, можно сохранить один DataFrame на лист ‘Продажи’, а другой на лист ‘Клиенты’, и все они окажутся в одном файле Excel.
Как сохранить числовые и текстовые данные в Excel без потери формата?
При экспорте через pandas большинство типов данных сохраняются корректно: числа остаются числами, строки — текстом. Если требуется особое форматирование, например, отображение дат или валют, можно использовать openpyxl после записи файла pandas. В openpyxl можно задать стиль ячейки, формат числа, ширину столбца и выравнивание, чтобы данные выглядели так, как нужно.
Что делать, если файл Excel не открывается после экспорта из Python?
Чаще всего проблема возникает из-за повреждения файла или неправильного расширения. Нужно убедиться, что файл сохраняется с расширением .xlsx и что используется актуальная версия библиотеки, поддерживающая этот формат. Иногда помогает открыть файл в Excel и пересохранить его вручную, чтобы проверить, корректно ли данные записаны. Также стоит проверить, что никакие процессы Excel не блокируют запись файла.
Можно ли добавлять новые данные в существующий Excel-файл без удаления старых?
Да, с помощью pandas и ExcelWriter в режиме append или с openpyxl можно открыть существующий файл, добавить новые листы или дополнить существующие. В pandas нужно указать mode=’a’ при создании ExcelWriter, чтобы данные добавлялись к уже существующим листам, а openpyxl позволяет работать напрямую с книгой Excel, добавляя строки или столбцы без удаления предыдущих данных.
Какие библиотеки Python лучше всего использовать для экспорта данных в Excel?
Для работы с Excel в Python часто используют библиотеки pandas и openpyxl. Pandas удобна для обработки и структурирования данных, а затем сохранения их в формате Excel через метод to_excel(). Openpyxl позволяет более детально работать с самим файлом Excel, например, настраивать стили ячеек, форматы дат и формулы. Если нужно просто быстро выгрузить таблицу, pandas будет проще, а для сложной настройки документа лучше подключить openpyxl.