CUDA предоставляет прямой доступ к вычислительным возможностям графических процессоров NVIDIA, позволяя Python-приложениям обрабатывать массивы данных в десятки раз быстрее, чем на CPU. Библиотеки, такие как Numba и CuPy, интегрируются с Python без необходимости переписывать код на C++ или использовать низкоуровневые API.
Для эффективного применения CUDA важно учитывать архитектуру GPU: количество ядер, размер видеопамяти и поддерживаемые версии Compute Capability. Numba позволяет компилировать Python-функции в параллельные ядра CUDA, а CuPy предоставляет интерфейс, совместимый с NumPy, что упрощает перенос существующих алгоритмов на GPU.
Оптимизация вычислений требует разбиения задач на блоки и сетки потоков, минимизации передачи данных между CPU и GPU и использования асинхронных операций. Реальное ускорение достигается при обработке массивов от 10⁵ элементов и выше, при этом для малых объемов данные о передаче могут нивелировать преимущества GPU.
При работе с CUDA в Python важно профилировать код с помощью инструментов, таких как Nsight Systems и nvprof, чтобы выявить узкие места и выбрать оптимальную стратегию распределения потоков. Это позволяет повысить эффективность даже для сложных задач линейной алгебры, обработки изображений и машинного обучения.
Установка и настройка среды CUDA для Python
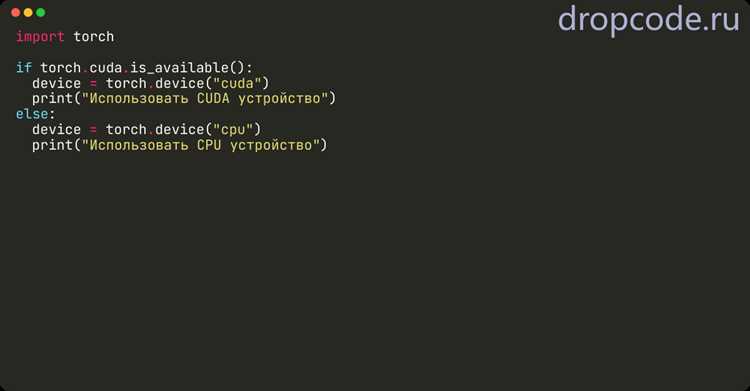
Для работы с CUDA в Python требуется видеокарта NVIDIA с архитектурой, поддерживаемой последней версией CUDA Toolkit. Проверить совместимость можно на официальной странице NVIDIA.
Скачивание CUDA Toolkit выполняется с сайта NVIDIA. Выбирайте версию, совместимую с вашей ОС и драйверами. Для Windows предпочтительно использовать exe-инсталлятор, для Linux – .run или пакетный менеджер (apt, yum). После установки обязательно проверить наличие переменной окружения CUDA_PATH, указывающей на каталог установки.
Следующий шаг – установка Python-библиотек. Основная библиотека для работы с CUDA – PyCUDA. Установка через pip выполняется командой: pip install pycuda. Альтернативно можно использовать CuPy для массивных вычислений, совместимый с NumPy синтаксисом: pip install cupy-cudaXX, где XX соответствует версии CUDA (например, cupy-cuda12x).
После установки необходимо проверить корректность работы среды. В Python выполните:
import pycuda.driver as cuda
cuda.init()
print(cuda.Device(0).name())
Команда должна вывести название вашей видеокарты. Если возникает ошибка, убедитесь, что драйвер NVIDIA установлен и соответствует версии CUDA Toolkit.
Для оптимизации среды рекомендуется обновлять драйверы GPU до последней стабильной версии, а также использовать виртуальное окружение Python для управления зависимостями. В Linux рекомендуется добавить LD_LIBRARY_PATH, включающий путь к библиотекам CUDA, для корректного связывания при запуске скриптов.
После настройки среды можно подключать библиотеки глубокого обучения и научных вычислений, такие как TensorFlow и PyTorch, с поддержкой CUDA, используя соответствующие версии с GPU-оптимизацией.
Использование библиотеки Numba для компиляции GPU-кода

Numba предоставляет возможность компилировать функции Python непосредственно в код, исполняемый на GPU, используя декоратор @cuda.jit. Для эффективного ускорения вычислений необходимо учитывать организацию потоков и блоков: оптимальная конфигурация часто определяется как threads_per_block = 256 и blocks_per_grid = (N + threads_per_block - 1) // threads_per_block, где N – размер массива данных.
Пример типичной функции для GPU:
from numba import cuda
import numpy as np
@cuda.jit
def vector_add(a, b, c):
idx = cuda.grid(1)
if idx < a.size:
c[idx] = a[idx] + b[idx]Для запуска функции необходимо выделить память на устройстве и скопировать данные:
N = 10**6
a = np.ones(N, dtype=np.float32)
b = np.ones(N, dtype=np.float32)
c = np.zeros(N, dtype=np.float32)
d_a = cuda.to_device(a)
d_b = cuda.to_device(b)
d_c = cuda.to_device(c)
threads_per_block = 256
blocks_per_grid = (N + threads_per_block - 1) // threads_per_block
vector_add[blocks_per_grid, threads_per_block](d_a, d_b, d_c)
d_c.copy_to_host()Numba позволяет использовать shared memory для ускорения операций с локальными массивами, уменьшая количество обращений к глобальной памяти. Например, для свёртки массивов или суммирования блоков данных рекомендуется хранить промежуточные результаты в cuda.shared.array.
Таблица оптимальных практик при использовании Numba на GPU:
| Практика | Рекомендация |
|---|---|
| Выбор размера блока | 256–512 потоков, кратно warp size (32) |
| Использование shared memory | Хранить промежуточные вычисления для уменьшения глобальных обращений |
| Проверка границ массива | Использовать if idx < size для предотвращения выхода за пределы |
| Параллельная трансформация массивов | Применять cuda.jit вместо циклов Python для каждого элемента |
| Профилирование | Использовать cuda.synchronize() и numba.cuda.profiler.start() для измерения времени исполнения |
Numba поддерживает интеграцию с NumPy и позволяет применять универсальные функции (ufuncs) на GPU через vectorize и guvectorize, что упрощает перенос существующего кода на ускорители без ручного управления памятью.
Передача данных между CPU и GPU без потерь скорости
Для минимизации задержек при передаче данных между CPU и GPU важно использовать выделенную память CUDA (pinned memory). Выделение host memory через cudaHostAlloc() позволяет GPU напрямую обращаться к данным без копирования через системный буфер, что снижает latency до 2–3× по сравнению с обычной памятью.
Использование асинхронных операций cudaMemcpyAsync() совместно с потоками CUDA (cudaStream_t) позволяет перекрывать вычисления и передачу данных. При этом важно следить, чтобы данные, передаваемые асинхронно, находились в pinned memory; обычная host memory не поддерживает полностью асинхронный режим.
Для больших массивов (>100 МБ) эффективнее разбивать их на блоки и передавать по частям с помощью нескольких потоков, чтобы GPU не простаивал, ожидая завершения передачи всего объема. Одновременно это уменьшает вероятность троттлинга PCIe.
Использование Unified Memory через cudaMallocManaged() удобно, но на практике оно медленнее, чем прямое использование pinned memory с асинхронными копиями. Для критически быстрых вычислений рекомендуется комбинировать managed memory для небольших структур и pinned memory для больших массивов.
Для многокарточных систем стоит применять Peer-to-Peer (P2P) копирование через cudaMemcpyPeerAsync(), что исключает прохождение данных через CPU и ускоряет передачу между GPU до 5× по сравнению с традиционным маршрутом через host.
Мониторинг пропускной способности PCIe и использование cudaDeviceSynchronize() только после завершения критичных блоков позволяет избежать блокировок, сохраняя максимальную скорость вычислений и передачи данных.
Параллельное выполнение циклов с помощью CUDA-потоков
CUDA позволяет распараллеливать итерации циклов на уровне потоков GPU, существенно ускоряя вычисления, особенно для массивных данных. Основная идея – разнести каждую итерацию цикла на отдельный поток, минимизируя зависимость между вычислениями.
Применение параллельных циклов в Python через библиотеку numba.cuda включает несколько ключевых шагов:
- Декорирование функции с
@cuda.jit, превращая её в CUDA-ядро. - Определение количества потоков на блок (
threadsperblock) и числа блоков (blockspergrid), исходя из размера данных. - Использование индексации потока через
cuda.grid(1)для привязки каждой итерации к конкретному потоку.
Пример эффективного распределения циклов:
from numba import cuda
import numpy as np
@cuda.jit
def vector_add(a, b, c):
idx = cuda.grid(1)
if idx < a.size:
c[idx] = a[idx] + b[idx]
n = 10_000_000
threadsperblock = 256
blockspergrid = (n + threadsperblock - 1) // threadsperblock
a = np.random.rand(n).astype(np.float32)
b = np.random.rand(n).astype(np.float32)
c = np.zeros_like(a)
vector_add[blockspergrid, threadsperblock](a, b, c)
Рекомендации для максимальной производительности:
- Использовать
float32вместоfloat64для уменьшения потребления памяти и ускорения операций. - Стараться выравнивать количество потоков с кратным 32, чтобы оптимизировать работу warp'ов.
- Минимизировать условные конструкции внутри циклов – каждая ветвь снижает параллельную эффективность.
- Разбивать большие массивы на блоки, если их размер превышает объем доступной памяти GPU.
- Использовать
cuda.synchronize()после завершения вычислений, если требуется точный порядок исполнения с CPU.
Такой подход позволяет ускорять обработку массивов на порядки по сравнению с последовательными циклами на CPU, особенно при вычислениях, где каждая итерация независима.
Оптимизация памяти GPU для больших массивов данных

При работе с большими массивами данных в CUDA критично управлять памятью GPU для предотвращения переполнений и снижения производительности. Основные подходы включают эффективное распределение памяти, минимизацию копирования между хостом и устройством и использование специализированных типов памяти.
- Выбор типа памяти: для временных массивов предпочтительнее использовать
cudaMallocManagedилиcudaMallocс явным управлением, чтобы контролировать перенос данных между хостом и устройством. - Пакетная обработка данных: разбивайте массивы на блоки размером, кратным 256 или 512 элементов, чтобы обеспечить выравнивание по warp и минимизировать неэффективные обращения к памяти.
- Стриминг данных: используйте CUDA streams для асинхронного копирования и вычислений. Например, копирование следующего блока данных в фоновой stream позволяет одновременно выполнять kernel на текущем блоке.
- Shared Memory: при доступе к большим массивам используйте shared memory для часто повторяющихся операций. Размер блока shared memory ограничен (обычно 48–96 КБ на SM), поэтому выбирайте подмассивы для кеширования.
- Пакетная сортировка и редукция: при суммировании или сортировке больших массивов применяйте иерархические алгоритмы с локальной обработкой в shared memory и финальной редукцией в глобальной памяти.
- Использование pinned memory: выделение хост-памяти через
cudaHostAllocускоряет transfer в device memory на 30–50% по сравнению с обычнымnumpyмассивом.
Эффективное управление памятью напрямую влияет на производительность. Минимизируйте количество аллокаций и освобождений памяти внутри циклов, используйте memory pool через cupy.cuda.memory или numba.cuda.pinned_array для повторного использования блоков.
- Планируйте размер массивов с учётом общей памяти GPU и shared memory.
- Используйте асинхронные копирования и streams для перекрытия вычислений и передачи данных.
- Оптимизируйте доступ к глобальной памяти через coalescing и выравнивание по 32 байтам на warp.
- Кэшируйте часто используемые данные в shared memory или регистры.
- Контролируйте использование memory pool для уменьшения фрагментации.
Следование этим правилам позволяет ускорить вычисления с большими массивами в 2–5 раз по сравнению с naïve реализацией и снижает риск ошибок out-of-memory при масштабировании задач.
Использование CuPy для ускорения линейной алгебры в Python

CuPy представляет собой библиотеку, полностью совместимую с NumPy, но с поддержкой выполнения вычислений на GPU через CUDA. Основное преимущество CuPy – возможность ускорять операции с большими матрицами без изменения синтаксиса привычного NumPy-кода.
Для создания массивов на GPU используется cupy.array(), а стандартные функции линейной алгебры, такие как cupy.dot(), cupy.linalg.inv() и cupy.linalg.eig(), работают аналогично NumPy, но вычисляются на графическом процессоре. Например, умножение матриц размером 10 000×10 000 на современном GPU выполняется в пределах нескольких сотен миллисекунд вместо секунд на CPU.
CuPy позволяет оптимизировать память через cupy.asarray(), что избегает лишнего копирования данных при переходе с NumPy на GPU. Для больших вычислений рекомендуется использовать streaming и asynchronous operations, чтобы выполнять несколько операций одновременно, минимизируя простои GPU.
При работе с CuPy важно контролировать размер блоков и сеток CUDA через cupy.ElementwiseKernel или cupy.RawKernel для сложных пользовательских операций. Это позволяет полностью использовать вычислительную мощность GPU, снижая время выполнения критических участков кода.
Для интеграции с существующими проектами на NumPy достаточно заменить import numpy as np на import cupy as cp и убедиться, что массивы создаются на GPU. При необходимости результат можно вернуть на CPU с помощью array.get().
CuPy также поддерживает линейную алгебру с разреженными матрицами через cupyx.scipy.sparse, что позволяет эффективно выполнять операции с большими разреженными графами и системами уравнений, недоступные для стандартного NumPy.
Использование CuPy рекомендуется там, где матрицы превышают 5 000×5 000 элементов или требуется многократное повторение вычислений, поскольку накладные расходы на перенос данных на GPU оправданы только при значительных объёмах вычислений.
Профилирование и отладка GPU-кода с NVIDIA Nsight
NVIDIA Nsight предоставляет инструменты для детального анализа производительности CUDA-программ на Python. Основная цель – выявление узких мест в вычислениях и оптимизация использования GPU-ресурсов.
Для начала работы необходимо установить Nsight Systems и Nsight Compute. Nsight Systems собирает трассировки выполнения ядра, управления памятью и потоками, позволяя выявить задержки между CPU и GPU. Nsight Compute анализирует отдельные ядра, отображая показатели инструкции на такт, использование регистров, occupancy и пропускную способность памяти.
При профилировании Python-кода с CUDA рекомендуется использовать функцию @cuda.jit с включением флага профилирования через Nsight. Запуск через команду nsys profile -o output python script.py создает подробную трассировку, которую можно открыть в Nsight Systems. В интерфейсе доступны графики загрузки SM, очередей памяти и задержек синхронизации потоков.
Для точечной оптимизации отдельных ядер используется Nsight Compute. Команда ncu --target-processes all python script.py собирает метрики по каждой функции, включая L1/L2 hit rate, DRAM utilization и warp execution efficiency. Анализ этих данных помогает корректировать размер блоков, использование shared memory и уменьшать divergent branching.
Рекомендуется объединять данные Nsight Systems и Nsight Compute: сначала выявлять узкие места на уровне всей программы, затем оптимизировать отдельные ядра. Также стоит использовать фильтры по потокам и временным диапазонам, чтобы исключить влияние фоновых процессов и системных задержек.
Для регулярного профилирования интегрируйте запуск Nsight в CI/CD, сохраняйте отчеты в формате .qdrep и автоматизируйте сравнение ключевых метрик между версиями кода. Это позволяет отслеживать деградацию производительности при внесении изменений.
Вопрос-ответ:
Что такое CUDA и как она взаимодействует с Python?
CUDA — это технология, которая позволяет использовать графические процессоры (GPU) для выполнения вычислений, обычно выполняемых на центральном процессоре (CPU). В Python с CUDA работают через специальные библиотеки, такие как Numba или PyCUDA. Эти библиотеки предоставляют интерфейс для передачи данных на GPU, выполнения параллельных вычислений и получения результатов обратно на CPU, что может значительно ускорить обработку больших массивов данных.
Какие типы задач в Python выигрывают от применения CUDA?
Наибольший эффект от CUDA наблюдается при обработке больших объемов данных, например, при численных расчетах, моделировании физических процессов, обучении нейронных сетей и работе с большими матрицами. Параллельная архитектура GPU позволяет выполнять множество одинаковых операций одновременно, поэтому задачи с высокой степенью повторяемости операций на больших массивах данных выигрывают больше всего.
Как настроить Python для работы с CUDA?
Для начала необходимо установить драйверы NVIDIA для вашей видеокарты, затем установить саму платформу CUDA. В Python чаще всего используют библиотеки Numba или PyCUDA. В случае Numba достаточно установить пакет через pip и пометить функции декоратором @cuda.jit для выполнения на GPU. PyCUDA требует более детальной настройки и работы с управлением памятью GPU, но предоставляет больше контроля над вычислительным процессом.
Существуют ли ограничения при использовании CUDA в Python?
Да, существуют несколько ограничений. Во-первых, CUDA работает только с видеокартами NVIDIA. Во-вторых, не все алгоритмы подходят для параллельной обработки — задачи с высокой зависимостью между вычислениями могут не ускоряться. Также необходимо учитывать объем видеопамяти: если данные не помещаются в память GPU, придется использовать разделение данных или обрабатывать их частями, что снижает ускорение.