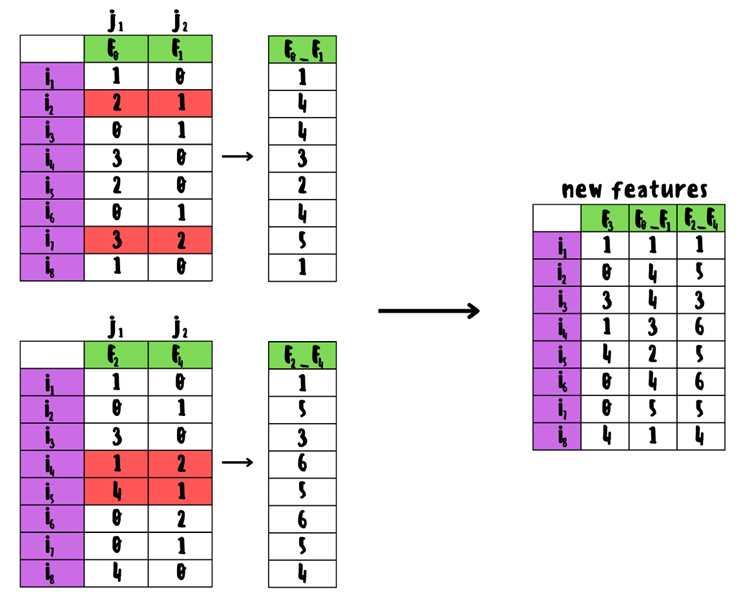
Градиентный бустинг – это метод ансамблирования, который строит модель последовательно, исправляя ошибки предыдущих деревьев решений. В отличие от простого бустинга, каждый следующий базовый алгоритм минимизирует градиент функции потерь, что обеспечивает более точную аппроксимацию целевой переменной. Для реализации на Python достаточно сочетания NumPy для матричных операций и базовых структур данных, без необходимости использования сторонних библиотек.
Ключевой этап работы градиентного бустинга – вычисление отрицательного градиента функции потерь для текущих прогнозов. На практике это означает, что для каждого наблюдения рассчитывается residual, который затем становится целевой переменной для обучения следующего дерева. На Python это реализуется через векторные операции NumPy, что позволяет ускорить вычисления на больших наборах данных.
Оптимизация модели требует внимательного выбора шага обучения (learning rate) и числа итераций (n_estimators). Слишком высокий шаг приводит к переобучению, слишком низкий – к медленной сходимости. Практика показывает, что learning rate = 0.05–0.1 и 100–500 деревьев позволяют достичь баланса между скоростью обучения и качеством прогноза.
Реализация градиентного бустинга на NumPy также включает вычисление среднего значения целевой переменной для инициализации модели, построение простого дерева на отрицательных градиентах и поэтапное обновление предсказаний. Такой подход обеспечивает прозрачность алгоритма, упрощает отладку и позволяет контролировать каждый шаг процесса обучения без скрытых оптимизаций сторонних библиотек.
Градиентный бустинг на Python и NumPy: принцип работы
Градиентный бустинг строит последовательность слабых моделей, обычно деревьев решений, каждая из которых корректирует ошибки предыдущих. Основной принцип – минимизация функции потерь методом градиентного спуска.
Алгоритм можно описать следующими шагами:
- Инициализация модели предсказанием константы, которая минимизирует функцию потерь (например, среднее для MSE).
- Вычисление отрицательного градиента функции потерь для каждого объекта обучающего набора – это показывает, куда нужно скорректировать предсказание.
- Обучение слабой модели на рассчитанных градиентах как на целевых значениях.
- Обновление общей модели с помощью добавления предсказания новой слабой модели, умноженного на коэффициент обучения learning_rate.
- Повторение шагов 2–4 до достижения заданного числа итераций или пока улучшение метрики не станет незначительным.
На Python с использованием NumPy реализация фокусируется на векторных операциях для ускорения расчетов:
- Хранение предсказаний всех объектов в одном массиве, обновление производится поэлементно через векторные операции.
- Вычисление градиента функции потерь как массивной операции:
grad = 2 * (y_pred - y_true)для MSE. - Обучение слабой модели на градиентах может быть реализовано через простые решения, например, построение деревьев вручную или с помощью библиотек типа
scikit-learnдля демонстрации. - Обновление модели:
y_pred += learning_rate * tree_pred, что позволяет контролировать шаг градиентного спуска.
Рекомендации по эффективной работе с NumPy:
- Использовать тип данных
float32для больших массивов, чтобы снизить потребление памяти. - Векторизовать все операции вместо циклов по элементам для ускорения расчетов.
- Контролировать learning_rate и глубину деревьев: слишком высокий шаг может привести к переобучению, слишком маленький – к медленной сходимости.
- Сохранять промежуточные предсказания для анализа сходимости и визуализации ошибок на каждом шаге.
Таким образом, градиентный бустинг на Python с NumPy строится как последовательное улучшение предсказаний через отрицательные градиенты, с акцентом на векторные вычисления и контроль параметров обучения.
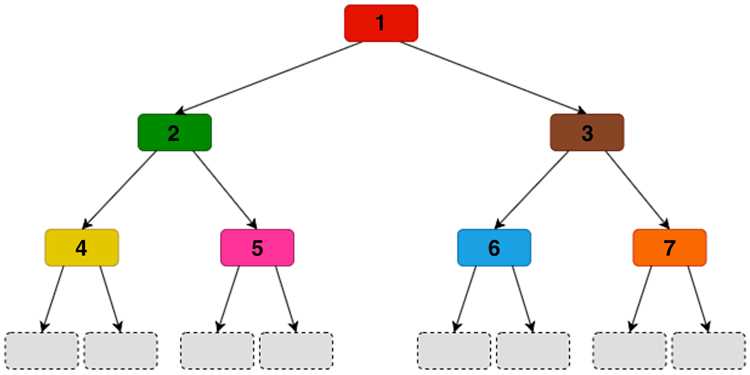
Реализация простого дерева решений на NumPy для бустинга
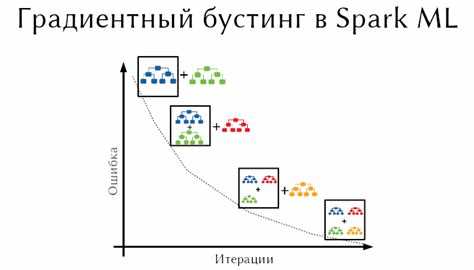
Для построения дерева решений в контексте градиентного бустинга важно сосредоточиться на эффективности разбиений и быстром вычислении ошибок. Основной принцип – рекурсивное деление данных по признакам, минимизирующее выбранную функцию потерь.
Сначала формируем массивы признаков X и целевой переменной y с использованием NumPy. Для регрессии часто применяется среднеквадратичная ошибка (MSE). Основная задача на каждом узле – найти признак j и порог t, которые минимизируют сумму MSE для левой и правой ветви:
MSE_split = MSE_left + MSE_right
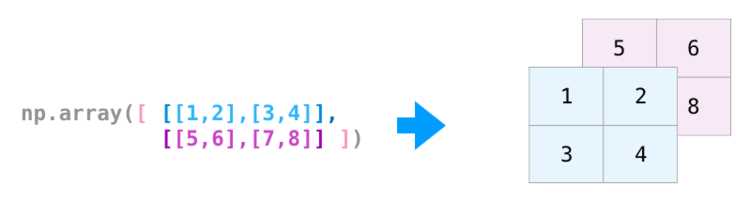
Оптимизация производится перебором всех уникальных значений признаков. Для ускорения вычислений рекомендуется использовать сортировку признаков один раз и векторные операции NumPy:
sort_idx = np.argsort(X[:, j])
X_sorted = X[sort_idx, j]
y_sorted = y[sort_idx]После сортировки легко вычислить кумулятивные суммы и средние для левой и правой части, что позволяет мгновенно оценивать MSE для всех потенциальных разбиений без явного цикла по каждому порогу.
Когда выбирается лучшее разбиение, формируем левый и правый узлы, повторяя процесс рекурсивно до достижения максимальной глубины дерева или минимального числа объектов в листе. В листе прогноз фиксируется как среднее целевых значений:
y_leaf = np.mean(y_leaf)
Для интеграции с градиентным бустингом полезно хранить структуру дерева в виде словаря с ключами: feature_index, threshold, left, right, value. Это позволяет быстро обходить дерево при вычислении предсказаний и градиентных обновлений.
Важная рекомендация: использовать масштабирование данных и ограничение глубины дерева. Даже простое дерево с 3–5 уровнями может эффективно уменьшить остаточную ошибку в бустинге, сохраняя скорость вычислений и предотвращая переобучение.
Вычисление граадиентов функции потерь вручную на Python
Для градиентного бустинга ключевой шаг – вычисление градиента функции потерь по предсказаниям модели. Рассмотрим пример с квадратичной функцией потерь (MSE). Пусть y – вектор истинных значений, y_pred – вектор предсказаний. Градиент L по y_pred вычисляется как dL/dy_pred = y_pred — y.
На Python с использованием NumPy это реализуется так:
import numpy as np
y = np.array([3.0, 5.0, 2.0])
y_pred = np.array([2.5, 4.5, 2.2])
gradient = y_pred - y
print(gradient) # [-0.5, -0.5, 0.2]
Для функции потерь LogLoss (для бинарной классификации) градиент вычисляется по формуле: dL/dy_pred = y_pred — y, где y_pred – прогноз вероятности класса 1, y – метка класса 0 или 1. Реализация на Python:
y = np.array([0, 1, 1])
y_pred = np.array([0.2, 0.8, 0.6])
gradient = y_pred - y
print(gradient) # [ 0.2, -0.2, -0.4 ]
Для пользовательских функций потерь градиент вычисляется как аналитическая производная по предсказаниям. Важно проверять размерность векторов y и y_pred, чтобы избежать ошибок broadcasting.
Рекомендации по производительности: использовать векторные операции NumPy, избегать циклов Python для больших массивов, предварительно кэшировать значения экспонент или логарифмов при повторных вычислениях, например для LogLoss или экспоненциальной функции потерь.
После вычисления градиента он используется как таргет для обучения слабого модели (дерева решений) на текущей итерации градиентного бустинга.
Пошаговое построение ансамбля слабых моделей
Градиентный бустинг строит ансамбль последовательно, добавляя слабые модели для корректировки ошибок предыдущих. Основная идея – минимизация функционала потерь методом градиентного спуска в пространстве функций.
1. Инициализация модели: Начинаем с простой модели, например, константного предсказания. Для регрессии это может быть среднее целевой переменной:
| y_pred0 | = mean(y) |
2. Вычисление градиента: Для каждого наблюдения считаем отрицательный градиент функции потерь по текущему предсказанию. Для MSE градиент прост – это разница между истинными значениями и предсказаниями:
| ri | = yi — y_predi |
3. Обучение слабой модели: Создаем новую слабую модель (например, дерево решений с глубиной 3–5), которая аппроксимирует рассчитанные градиенты:
| hm(x) | ≈ ri |
4. Вычисление коэффициента масштаба: Оптимизируем параметр γ, минимизирующий функцию потерь после добавления новой модели:
| γm | = argmin Σ L(yi, y_predi + γ * hm(xi)) |
5. Обновление предсказаний: Интегрируем новую слабую модель в ансамбль с коэффициентом обучения η:
| y_pred | = y_pred + η * γm * hm(x) |
6. Повторение цикла: Шаги 2–5 повторяются до достижения заданного числа моделей M или пока ошибка на валидации не перестанет снижаться.
Рекомендации:
- Выбирать небольшую глубину деревьев (3–5), чтобы модели оставались слабыми.
- Использовать η = 0.05–0.2, чтобы градиентный шаг был плавным и предотвращал переобучение.
- Регулярно проверять метрики на отложенной выборке после каждой итерации.
- Для нестандартных функций потерь корректировать градиентный шаг соответствующим образом.
Обновление прогнозов с учётом градиента ошибки

В градиентном бустинге каждый шаг обучения направлен на минимизацию функции потерь через корректировку текущих прогнозов. Основная идея – вычислить градиент ошибки для каждого объекта и использовать его как целевую переменную для следующего слабого модели.
Алгоритм обновления прогнозов на Python с использованием NumPy можно описать следующим образом:
- Вычисляем текущие прогнозы:
y_pred = np.full(y.shape, y.mean()), гдеy– вектор истинных значений. - Вычисляем градиенты ошибки:
- Для MSE:
grad = y - y_pred - Для логистической регрессии:
grad = y / (1 + np.exp(y_pred * y))
- Для MSE:
- Обучаем слабую модель на градиентах:
tree.fit(X, grad) - Обновляем прогнозы с коэффициентом обучения
eta:y_pred += eta * tree.predict(X) - Повторяем шаги 2–4 до достижения заданного числа итераций или минимизации ошибки.
Рекомендации для точного обновления прогнозов:
- Использовать малые значения
eta(0.01–0.1) для предотвращения переобучения. - Нормализовать градиенты при нестабильных функциях потерь.
- Сохранять отдельный массив текущих прогнозов для мониторинга прогресса обучения.
- Проверять распределение градиентов: резкие выбросы могут указывать на ошибки в расчётах функции потерь.
Такой подход обеспечивает целенаправленное улучшение прогноза, поскольку каждая новая модель компенсирует конкретные ошибки предыдущих. Контроль градиентов и коэффициента обучения позволяет добиться оптимального баланса между скоростью обучения и стабильностью прогноза.
Настройка скорости обучения и числа итераций без библиотек
В градиентном бустинге на Python с использованием только NumPy скорость обучения (learning rate) контролирует долю предсказанной поправки на каждом шаге. Для численных экспериментов оптимальное значение обычно находится в диапазоне 0.01–0.1. Меньшее значение снижает риск переобучения, но требует большего числа итераций.
Число итераций (n_estimators) напрямую влияет на сходимость модели. Для небольших наборов данных достаточно 100–300 итераций, для больших – 500–1000. Проверка сходимости выполняется через вычисление среднеквадратичной ошибки на тренировочном наборе после каждой итерации.
Практический подход без библиотек: инициализируйте базовую модель средним целевой переменной, затем на каждой итерации вычисляйте остатки. Обновляйте прогнозы с учетом скорости обучения: y_pred_new = y_pred_old + learning_rate * delta. Мониторинг ошибки позволяет корректировать learning rate и число итераций без гиперпараметрического перебора.
Для автоматической остановки используйте критерий: если изменение ошибки меньше 1e-5 на 10 последовательных итерациях, итерации можно завершить. Это экономит ресурсы и предотвращает переобучение.
Экспериментируя с разными комбинациями скорости обучения и числа итераций, фиксируйте метрики после каждой итерации. Так можно построить график зависимости ошибки от итераций и выбрать комбинацию с минимальной ошибкой на валидации, полностью обходясь без сторонних библиотек.
Оценка качества модели с использованием собственных метрик на NumPy
Для точной оценки качества градиентного бустинга можно реализовать метрики напрямую на NumPy, что исключает накладные расходы внешних библиотек и повышает контроль над вычислениями. Основные метрики – среднеквадратичная ошибка (MSE), средняя абсолютная ошибка (MAE) и коэффициент детерминации R².
Пример реализации MSE на NumPy:
import numpy as np
def mse(y_true, y_pred):
return np.mean((y_true - y_pred) 2)
Для MAE достаточно заменить возведение в квадрат на модуль:
def mae(y_true, y_pred):
return np.mean(np.abs(y_true - y_pred))
R² отражает долю объясненной дисперсии:
def r2_score(y_true, y_pred):
ss_res = np.sum((y_true - y_pred) 2)
ss_tot = np.sum((y_true - np.mean(y_true)) ** 2)
return 1 - ss_res / ss_tot
При обучении градиентного бустинга важно оценивать метрики на каждой итерации. Для этого можно хранить прогнозы всех базовых моделей и вычислять метрики накопительно. Это позволяет обнаруживать переобучение раньше, чем на финальном предсказании.
Рекомендуется использовать метрики, соответствующие задаче. Для регрессии – MSE и MAE, для классификации можно реализовать точность, F1-score и логарифмическую потерю через NumPy, используя бинарные или многоклассовые индикаторы. Важна проверка корректности размерностей массивов и исключение NaN при вычислениях.
Собственные метрики на NumPy дают возможность экспериментировать с весами ошибок, например, усиливать штраф за большие отклонения, что невозможно при стандартных вызовах sklearn. Это особенно полезно при работе с несбалансированными данными или редкими целевыми событиями.
Вопрос-ответ:
Что такое градиентный бустинг и как он работает на базовом уровне?
Градиентный бустинг — это метод последовательного построения моделей, чаще всего деревьев решений, где каждая следующая модель исправляет ошибки предыдущих. На Python с использованием NumPy можно реализовать простой вариант, вычисляя градиенты функции потерь по текущим предсказаниям и подбирая новые деревья, которые уменьшают эти ошибки. Процесс повторяется несколько раз, и итоговое предсказание получается суммой предсказаний всех моделей.
Почему для реализации градиентного бустинга часто используют NumPy?
NumPy предоставляет быстрые и оптимизированные операции с массивами, что позволяет эффективно вычислять ошибки, градиенты и обновлять предсказания для всех объектов сразу. В градиентном бустинге часто приходится работать с большими матрицами значений, а Python без NumPy был бы слишком медленным для таких операций. С помощью NumPy можно легко реализовать обучение на уровне элементов данных и матричных вычислений, что ускоряет процесс построения моделей.
Как выбирается функция потерь для градиентного бустинга и на что это влияет?
Функция потерь определяет, как измеряется ошибка предсказания. Для задачи регрессии часто используют среднеквадратичную ошибку, для классификации — логарифмическую. Выбор функции потерь напрямую влияет на то, какие градиенты будут вычисляться и как новые деревья будут корректировать предсказания. Например, при использовании MSE градиенты будут просто разницей между предсказанием и истинным значением, а при логарифмическом потере для классификации градиенты учитывают вероятность классов.
Можно ли реализовать градиентный бустинг полностью на Python без сторонних библиотек?
Да, это возможно, но такой вариант будет медленнее по сравнению с библиотеками вроде scikit-learn или XGBoost. На Python можно написать реализацию, используя только встроенные структуры данных и NumPy для работы с массивами. Основные шаги включают инициализацию простого базового предсказателя, вычисление градиентов ошибки, построение простых деревьев решений для исправления ошибок и суммирование предсказаний. Такая реализация хороша для обучения и понимания принципа работы, но не подходит для больших наборов данных.