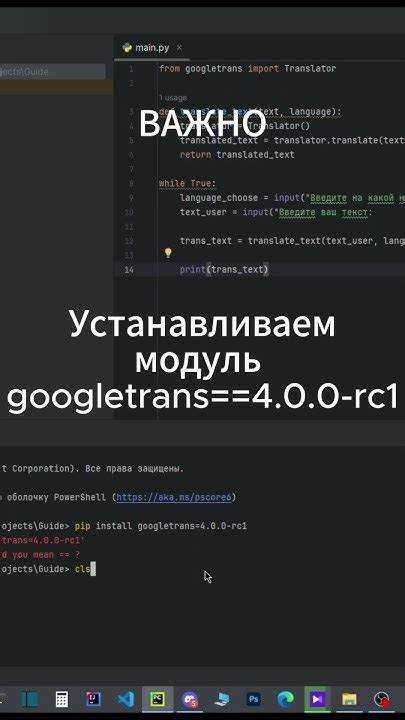
Для разработки эффективного переводчика на Python важно определить тип перевода: словарный, контекстный или нейросетевой. На старте рекомендуется использовать библиотеку googletrans для быстрых прототипов, а затем переходить к transformers и моделям типа BERT или MarianMT для глубокого обучения и точного контекстного перевода.
Обработка текста требует нормализации: удаление лишних пробелов, приведение символов к единому регистру, замена специальных знаков. Для этого удобно использовать regex и nltk. Важный момент – корректная работа с кодировками UTF-8, особенно при переводе на языки с нелатинскими символами.
Для повышения качества перевода стоит интегрировать систему тестирования: контроль корректности слов, проверка грамматики и синтаксиса. Использование pytest и написание модульных тестов для ключевых функций позволит оперативно выявлять ошибки и улучшать точность модели.
Выбор библиотеки для работы с API переводов и её настройка
Для интеграции перевода в Python-проект критически важно выбрать библиотеку, которая поддерживает современные API и обеспечивает стабильную работу. Наиболее востребованные варианты:
- googletrans – неофициальный клиент Google Translate. Поддерживает более 100 языков, не требует API-ключа, но нестабилен при частых запросах.
- DeepL API через библиотеку
deepl– точный перевод с продвинутой настройкой стиля текста. Требует API-ключ, ограничен тарифами. - Microsoft Translator Text API через библиотеку
mstranslator– интеграция с Azure, поддержка пакетной обработки и форматов JSON.
Для проекта с реальными нагрузками рекомендуется использовать официальные API (DeepL или Microsoft), так как они гарантируют стабильность и актуальность языковых моделей.
Настройка библиотеки включает несколько этапов:
- Установка через pip, например:
pip install deeplилиpip install mstranslator. - Создание учетной записи и получение API-ключа на соответствующем сервисе.
- Инициализация клиента с ключом:
- Проверка работоспособности через тестовый запрос:
- Настройка дополнительных параметров: стиль перевода (
formal/informal), пакетная обработка, лимит символов.
import deepl
translator = deepl.Translator("ВАШ_API_КЛЮЧ")result = translator.translate_text("Привет, мир!", target_lang="EN")
print(result.text)Для локальной разработки можно подключить googletrans для быстрых тестов, но для продакшена лучше выбирать официальные API с ключом. Это обеспечит предсказуемую производительность и актуальность переводов.
Создание функции отправки текста на перевод и обработки ответа

Функция отправки текста на перевод должна принимать три обязательных параметра: текст, исходный язык и целевой язык. Для взаимодействия с API используем библиотеку requests. Важно формировать корректный JSON-запрос и указывать заголовки Content-Type: application/json и авторизационный токен, если он требуется.
Пример структуры запроса:
{
"source_text": "Пример текста",
"source_lang": "ru",
"target_lang": "en"
}
После отправки запроса необходимо проверять код ответа сервера. Для успешного перевода это обычно 200. Если код отличается, функция должна возвращать подробное сообщение об ошибке, включая текст ответа и HTTP-статус.
Обработка ответа заключается в извлечении переведённого текста из JSON-поля, которое чаще всего называется translated_text или аналогично. Рекомендуется предусмотреть проверку наличия этого поля, чтобы избежать ошибок KeyError при некорректном формате ответа.
Функция может возвращать переведённый текст напрямую или словарь с дополнительной информацией: исходный текст, целевой язык и статус запроса. Такой подход облегчает логирование и последующую обработку ошибок.
Добавление поддержки нескольких языков и определение исходного языка

Для поддержки нескольких языков в переводчике на Python удобно использовать словарь с кодами языков ISO 639-1 и соответствующими функциями перевода. Например, структура может выглядеть так: languages = {'en': 'Английский', 'fr': 'Французский', 'de': 'Немецкий', 'ru': 'Русский'}. Это позволяет легко добавлять новые языки без изменения логики приложения.
Определение исходного языка можно реализовать с помощью библиотеки langdetect. Она анализирует текст и возвращает код языка. Пример использования: from langdetect import detect; source_lang = detect(text). Для текстов меньше 20 символов рекомендуется проверять результат несколько раз, так как точность падает на коротких строках.
После определения исходного языка стоит реализовать проверку совпадения с целевым языком, чтобы избежать ненужного перевода. Например, если source_lang == target_lang, перевод не выполняется, а текст возвращается как есть.
Для удобства пользователя можно добавить функцию автозаполнения целевых языков на основе выбранного исходного, исключая совпадение. Также рекомендуется поддерживать возможность ручного выбора языка через аргументы функции или интерфейс, чтобы обеспечивать точность перевода специализированных терминов.
При работе с несколькими языками важно учитывать кодировку текста. Python 3 использует UTF-8 по умолчанию, но при чтении файлов из внешних источников стоит явно указывать encoding='utf-8', чтобы корректно обрабатывать символы кириллицы, акцентов и специальных знаков.
Для масштабирования проекта с несколькими языками удобно использовать отдельные файлы словарей или JSON-конфигурации для каждого языка. Это позволяет расширять поддержку без изменения основной логики перевода и упрощает интеграцию новых сервисов машинного перевода.
Обработка ошибок и ограничений API при массовом переводе

При работе с API перевода критически важно отслеживать коды ответа сервера. 429 означает превышение лимита запросов, 500–502 указывают на внутренние ошибки сервера, 403 и 401 сигнализируют о проблемах с ключом или правами доступа.
Для массового перевода необходимо внедрять механизм повторных попыток с экспоненциальной задержкой. Например, при 429 стоит повторить запрос через 1, 2, 4, 8 секунд с максимумом 5 попыток. Это снижает вероятность блокировки и сохраняет стабильность обработки.
Разделение текста на пакеты не более 1000–2000 символов или 50–100 строк одновременно уменьшает вероятность превышения лимита API и повышает скорость обработки за счет параллельной отправки нескольких пакетов с контролем concurrency.
Логи ошибок должны содержать оригинальный текст, код ошибки, время и количество повторов. Это упрощает диагностику и позволяет корректно пропускать проблемные фрагменты без остановки всего процесса.
Для предотвращения блокировки рекомендуется хранить счетчик запросов за минуту и час. Если текущий лимит близок к максимуму, скрипт должен приостанавливать отправку до восстановления квоты.
При массовых переводах полезно использовать кэширование уже переведенных сегментов. Это уменьшает количество повторных обращений к API и экономит лимиты, особенно при работе с повторяющимся текстом.
Обработка нестандартных символов и кодировок обязана быть встроена на этапе подготовки текста. Неправильная кодировка часто вызывает 400 или 422 ошибки, что замедляет процесс и требует ручной корректировки.
Для тестирования массового перевода рекомендуется сначала прогонять скрипт на небольших выборках (500–1000 строк), отслеживая все типы ошибок и их обработку. Это позволяет выявить узкие места до запуска полноценной обработки.
Сохранение переведённых текстов в файлы или базы данных
Для хранения переведённых текстов можно использовать как файловую систему, так и реляционные или NoSQL базы данных. В Python работа с файлами реализуется через встроенные функции `open()`, `write()` и `close()`. Для сохранения больших объёмов текста рекомендуется использовать кодировку UTF-8, чтобы избежать проблем с символами разных языков:
with open('translated.txt', 'w', encoding='utf-8') as f:
f.write(переведённый_текст)
Для многократного добавления текста вместо перезаписи используйте режим `’a’` (append). Для структурированных данных удобнее сохранять переводы в формате JSON, что упрощает последующую обработку и загрузку:
import json
data = {'original': исходный_текст, 'translated': переведённый_текст}
with open('translations.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False) + '\n')
Если требуется централизованное хранение и быстрый доступ, стоит использовать базы данных. Для реляционных БД (SQLite, PostgreSQL) структура таблицы может включать поля: `id`, `original_text`, `translated_text`, `timestamp`. В SQLite подключение и запись выполняются так:
import sqlite3
conn = sqlite3.connect('translations.db')
cursor = conn.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS translations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
original_text TEXT,
translated_text TEXT,
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP)''')
cursor.execute('INSERT INTO translations (original_text, translated_text) VALUES (?, ?)',
(исходный_текст, переведённый_текст))
conn.commit()
conn.close()
Для NoSQL баз, таких как MongoDB, запись документов происходит через библиотеку `pymongo`:
from pymongo import MongoClient
client = MongoClient('mongodb://localhost:27017/')
db = client['translation_db']
collection = db['translations']
collection.insert_one({'original': исходный_текст, 'translated': переведённый_текст, 'timestamp': datetime.now()})
При выборе метода хранения учитывайте объём данных и необходимость поиска по тексту. Файлы удобны для простых логов и архивов, реляционные БД подходят для сложных запросов и аналитики, а NoSQL оптимальны для динамических структур и быстрого масштабирования.
Создание простой командной оболочки для интерактивного перевода

Для организации интерактивного перевода в командной строке используйте встроенную функцию input() для получения текста от пользователя и цикл while True для непрерывной работы оболочки. Начните с импорта модуля перевода, например, собственного класса Translator, реализующего метод translate(text, target_language).
Создайте цикл, который запрашивает ввод текста и целевой язык. Пример структуры:
from translator import Translator
translator = Translator()
while True:
text = input("Введите текст для перевода: ")
if text.lower() == "выход":
break
target = input("Введите код языка (например, 'en' или 'ru'): ")
try:
result = translator.translate(text, target)
print("Перевод:", result)
except Exception as e:
print("Ошибка перевода:", e)
Обеспечьте обработку исключений при неверных кодах языка или пустых строках. Рекомендуется добавлять проверку длины текста и ограничение символов для предотвращения зависания при длинных вводах. Для удобства пользователя можно реализовать сокращения языков и команд, например, ‘выход’ для завершения и ‘список’ для отображения доступных кодов языков.
Если планируется работа с внешними API, включите проверку соединения и обработку тайм-аутов. Для ускорения разработки используйте модуль argparse, чтобы при запуске оболочки можно было задавать язык по умолчанию и включать режим отладки для отслеживания ошибок в переводе.
В завершение тестируйте оболочку на разных комбинациях языков, учитывая особенности кодировок UTF-8 и потенциальные ошибки при работе с неанглийскими символами, чтобы гарантировать стабильность интерактивного перевода.
Вопрос-ответ:
Какие библиотеки Python подходят для создания базового переводчика?
Для реализации простого переводчика можно использовать библиотеку `googletrans`, которая предоставляет доступ к API Google Translate без необходимости сложной настройки. Ещё одним вариантом является `translate`, поддерживающая несколько сервисов. Эти библиотеки позволяют быстро получать переводы текста, обрабатывая как отдельные слова, так и целые предложения. При выборе стоит обратить внимание на поддерживаемые языки и частоту обновления словарей.
Как обрабатывать текст перед переводом, чтобы результат был точнее?
Перед отправкой текста на перевод важно удалить лишние пробелы, спецсимволы и перевести все символы в единый регистр. Также полезно разбивать длинные тексты на предложения или абзацы, так как многие сервисы точнее работают с короткими фрагментами. Если в тексте встречаются сокращения или специфические термины, можно создать словарь замен, чтобы сервис корректно их интерпретировал.
Можно ли создать оффлайн-переводчик на Python без подключения к интернету?
Да, для этого используют локальные модели машинного перевода. Например, `Argos Translate` или модели на базе `OpenNMT` позволяют устанавливать необходимые словари и модели на компьютер. Такой подход требует больше памяти и времени на обучение модели, но обеспечивает независимость от сети и позволяет работать с конфиденциальными текстами.
Как добавить поддержку нескольких языков в одном переводчике?
Для поддержки нескольких языков в одной программе стоит хранить список доступных языков и их коды. При вводе текста пользователь может выбирать язык оригинала и язык перевода. В коде достаточно передавать эти параметры в библиотеку или API, чтобы получать перевод на нужный язык. Можно также добавить автопределение языка исходного текста, используя встроенные функции библиотек или отдельные инструменты распознавания.