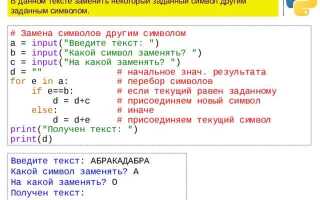
В Python строки представляют собой последовательности символов, доступ к которым возможен с помощью индексов. Каждый символ имеет уникальное положение, начиная с нуля. Для извлечения конкретного символа используется синтаксис string[index], где index может быть положительным или отрицательным, что позволяет получать символы с начала и конца строки соответственно.
Для получения подстроки применяется срез: string[start:stop:step]. Параметр start задает начальный индекс, stop – индекс окончания, step – шаг. Например, string[2:8:2] вернет каждый второй символ в диапазоне от третьего до восьмого включительно, что позволяет эффективно извлекать регулярные шаблоны символов.
Методы split() и join() полезны для извлечения символов по разделителям и их объединения обратно в строку. Функция enumerate() облегчает получение индексов при итерации по символам, что особенно удобно для фильтрации по условиям, например, извлечения всех цифр или букв из строки.
При работе с Unicode и многобайтовыми символами важно учитывать, что один визуальный символ может занимать несколько позиций в строке. Использование unicodedata позволяет корректно определять и извлекать такие символы без риска искажения данных.
Доступ к отдельным символам по индексу
В Python строки индексируются с нуля: первый символ имеет индекс 0, второй – 1 и так далее. Для обращения к символу используется квадратные скобки: символ = строка[индекс]. Например, буква = "Python"[2] вернёт 't'.
Допускаются отрицательные индексы. -1 указывает на последний символ, -2 – на предпоследний. Это удобно при работе с переменной длиной строкой: буква = "Python"[-1] вернёт 'n'.
Индексация за пределами длины строки вызывает IndexError. Перед доступом можно проверить длину через len(строка), чтобы избежать ошибок.
Для безопасного получения символа без исключения можно использовать срезы: символ = строка[индекс:индекс+1]. Если индекс выходит за границы, вернётся пустая строка, что предотвращает прерывание программы.
Доступ к символу по индексу возвращает строку длиной 1, которую можно использовать для операций сравнения, конкатенации или передачи в функции, работающие с отдельными символами.
Использование индексов в циклах позволяет обходить строку по символам: for i in range(len(строка)): print(строка[i]) – эффективный метод при необходимости работы с позициями символов.
Использование срезов для получения подстрок

Срезы в Python позволяют извлекать подстроки, указывая начальный и конечный индексы. Синтаксис выглядит как string[start:stop], где start – индекс первого символа, включаемого в подстроку, а stop – индекс, на котором срез заканчивается, но символ с этим индексом не включается.
Пример: text = «Python». Выражение text[1:4] вернет «yth», так как извлекаются символы с индексами 1, 2 и 3.
Если start пропущен, срез начинается с начала строки. Например, text[:3] даст «Pyt». Если пропущен stop, подстрока будет идти до конца: text[2:] → «thon».
Срезы поддерживают отрицательные индексы, отсчитываемые от конца строки. text[-4:-1] вернет «tho», начиная с четвертого символа с конца и до предпоследнего.
Для пропуска символов используется третий параметр step: text[::2] вернет каждый второй символ строки, результат – «Pto». Отрицательный шаг позволяет перевернуть строку: text[::-1] → «nohtyP».
Срезы эффективны для извлечения фиксированных частей строки, обработки подстрок перед анализом и получения регулярных интервалов символов без использования циклов. Важно проверять корректность индексов: Python не вызывает ошибок, если start или stop выходят за пределы строки – просто возвращается максимально возможная подстрока.
Извлечение символов с шагом через срезы

В Python срезы позволяют извлекать символы из строки с указанием начального индекса, конечного и шага: строка[начало:конец:шаг]. Шаг определяет, через сколько символов будет производиться выборка. Например, s = "abcdefgh", s[::2] вернёт 'aceg', пропуская каждый второй символ.
Отрицательный шаг позволяет идти в обратном направлении: s[::-1] полностью инвертирует строку. Комбинации отрицательных и положительных индексов дают гибкость при извлечении подстрок с заданным интервалом, например, s[5:0:-2] вернёт 'fdb', начиная с шестого символа и идя к первому через один символ.
При работе с большими строками рекомендуется явно указывать начало и конец, чтобы избежать неожиданных результатов при отрицательном шаге. Если индекс выхода за границы строки, Python автоматически корректирует его, что предотвращает ошибки.
Срезы с шагом особенно эффективны при фильтрации символов по шаблону, создании новых строк с регулярными интервалами или обработке данных, где важна позиционная выборка. Для динамических шагов можно использовать переменные: step = 3; s[::step] выбирает каждый третий символ без необходимости ручного перебора.
Важно помнить, что срезы создают новую строку, не изменяя исходную, что делает их безопасными для многократного использования и комбинирования с другими методами обработки строк, например .upper() или .replace().
Поиск и извлечение символов по условию

Для выборки символов по условию используют генераторы списков: [c for c in s if c.isdigit()] извлекает все цифры, [c for c in s if c.isalpha()] – все буквы. Для объединения результатов в строку применяется ''.join(...).
Регулярные выражения через модуль re позволяют искать сложные шаблоны: re.findall(r'[A-Z]{2,}', s) находит последовательности заглавных букв длиной две и более.
Для фильтрации по позиции символа используют enumerate: [c for i, c in enumerate(s) if i % 2 == 0] извлекает символы на четных позициях.
Комбинация условий через логические операторы: [c for c in s if c.isdigit() or c in 'ABC'] выбирает цифры и конкретные буквы одновременно.
Для больших строк применяют генераторы вместо списков: (c for c in s if c.islower()) создаёт символы по требованию, сокращая использование памяти.
Извлечение символов с помощью регулярных выражений
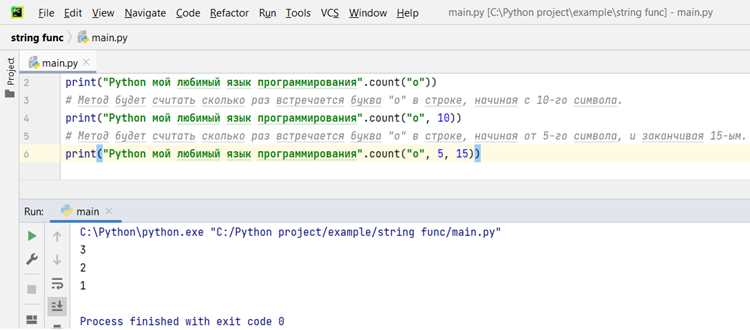
Регулярные выражения (regex) позволяют извлекать символы и последовательности из строк по строго заданным шаблонам. В Python для работы с ними используется модуль re.
Основные функции для извлечения символов:
re.findall(pattern, string)– возвращает список всех непересекающихся совпадений.re.search(pattern, string)– находит первое совпадение и возвращает объектMatch.re.match(pattern, string)– проверяет совпадение только в начале строки.re.finditer(pattern, string)– возвращает итератор объектовMatch, удобен для постобработки.
Примеры извлечения символов:
- Извлечение всех цифр:
re.findall(r'\d', 'a1b2c3')вернёт['1','2','3']. - Извлечение всех букв:
re.findall(r'[a-zA-Z]', 'a1B2c3')вернёт['a','B','c']. - Извлечение гласных:
re.findall(r'[aeiouAEIOU]', 'Python is fun')вернёт['o','i','u']. - Извлечение символов перед цифрой:
re.findall(r'(.)\d', 'a1b2c3')вернёт['a','b','c'].
Рекомендации при работе с регулярными выражениями:
- Для одиночных символов используйте классы символов:
[abc]или диапазоны[a-z]. - Для исключения символов используйте
[^...], например,[^0-9]извлекает всё, кроме цифр. - Используйте группировки
(...)для выборки конкретных подстрок внутри совпадения. - Применяйте необязательные символы
?и квантификаторы*,+для гибкой выборки повторяющихся символов. - Для работы с юникодными символами указывайте флаг
re.UNICODE, особенно для кириллицы или специальных символов.
Регулярные выражения позволяют создавать точные правила для извлечения символов, что особенно полезно при парсинге текстов, обработке логов и фильтрации данных.
Преобразование строки в список для манипуляций
Пример:
text = "Python"
chars = list(text)
Теперь chars содержит ['P', 'y', 't', 'h', 'o', 'n'] и готов к модификации.
После преобразования можно изменять элементы по индексу, добавлять новые символы с помощью append() или вставлять с помощью insert():
chars[0] = 'p'
chars.append('!')
Результат: ['p', 'y', 't', 'h', 'o', 'n', '!']
Для возврата к строке используется метод join():
new_text = ''.join(chars)
new_text теперь равен 'python!'.
При работе с длинными строками и частыми модификациями преобразование в список снижает накладные расходы, так как операции над списками выполняются быстрее, чем последовательное создание новых строк.
Также для специальных задач, например обработки слов, можно использовать split() для создания списка слов и последующей конкатенации с join().
Удаление и выборка символов с помощью методов строк
Python предоставляет несколько встроенных методов для точечного удаления и выборки символов в строках. Основные методы для удаления символов включают strip(), lstrip() и rstrip(). Они удаляют указанные символы с начала, конца или с обеих сторон строки.
Пример использования:
text = " пример "
text.strip() # Результат: «пример»
text.lstrip() # Результат: «пример «
text.rstrip() # Результат: » пример»
Методы replace() и translate() позволяют удалять или заменять конкретные символы по всей строке. replace() заменяет все вхождения одного символа или подстроки на другой, а translate() использует таблицу преобразований для массовых замен или удаления.
Пример удаления символов:
text = "Привет, мир!"
text.replace(",", "") # Результат: «Привет мир!»
text.translate(str.maketrans("", "", "!")) # Результат: «Привет, мир»
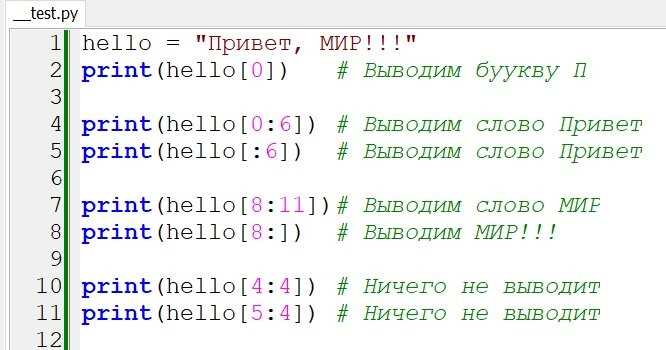
Для выборки отдельных символов и срезов используется синтаксис индексов string[start:stop:step]. Можно извлекать диапазоны символов, начиная с отрицательных индексов, что удобно для работы с концом строки.
Примеры выборки:
text = "Python"
text[0] # Первый символ: «P»
text[-1] # Последний символ: «n»
text[1:4] # Срез с 2-го по 4-й символ: «yth»
text[::2] # Каждый второй символ: «Pto»
| Метод | Назначение | Пример |
|---|---|---|
| strip() | Удаление пробелов или указанных символов с обеих сторон строки | " тест ".strip() → «тест» |
| lstrip() | Удаление пробелов или символов слева | " тест".lstrip() → «тест» |
| rstrip() | Удаление пробелов или символов справа | "тест ".rstrip() → «тест» |
| replace(old, new) | Замена или удаление символов | "а,б,в".replace(",", "") → «абв» |
| translate() | Удаление или массовая замена символов с таблицей преобразований | "abc!".translate(str.maketrans("", "", "!")) → «abc» |
| Индексы и срезы | Выбор отдельных символов или диапазонов | "Python"[1:4] → «yth» |
Вопрос-ответ:
Как получить один конкретный символ из строки в Python?
В Python строки индексируются с нуля, поэтому для получения символа используется квадратные скобки с указанием позиции. Например, строка s = «Python» — s[0] вернёт ‘P’, а s[3] — ‘h’. Также можно использовать отрицательные индексы: s[-1] вернёт последний символ, в данном случае ‘n’.
Можно ли извлечь несколько символов сразу?
Да, для этого применяется срез (slice). Синтаксис выглядит так: s[start:end:step], где start — начальный индекс, end — индекс окончания (не включая его), а step — шаг. Например, s = «Python»; s[1:4] вернёт ‘yth’, а s[::2] вернёт каждый второй символ — ‘Pto’.
Как извлечь символы с конца строки?
Для этого удобно использовать отрицательные индексы. s[-1] — последний символ, s[-2] — предпоследний. Можно комбинировать срезы с отрицательными индексами: s[-4:-1] вернёт три символа с конца, исключая последний. Такой подход помогает обходиться без вычисления длины строки.
Что произойдёт, если указать индекс за пределами строки?
Если обратиться к символу напрямую, например s[10] при длине строки 6, Python выдаст ошибку IndexError. При использовании срезов выход за пределы безопасен: s[2:10] вернёт все доступные символы до конца строки без ошибки.
Можно ли извлекать символы в обратном порядке?
Да, срезы позволяют указывать отрицательный шаг. Например, s = «Python»; s[::-1] вернёт ‘nohtyP’. Также можно комбинировать срез с отрицательными индексами, чтобы взять часть строки в обратном порядке, например s[4:1:-1] вернёт символы с позиции 4 до 2 включительно в обратной последовательности.
Как получить конкретный символ из строки в Python?
В Python строки ведут себя как списки символов, поэтому для извлечения конкретного символа используется индекс. Индексация начинается с нуля, то есть первый символ имеет индекс 0, второй — 1 и так далее. Например, если есть строка text = "Пример", то text[0] вернёт символ «П», а text[3] — «м». Также можно использовать отрицательные индексы: text[-1] даст последний символ строки.
Можно ли извлечь несколько символов сразу, а не по одному?
Да, для этого применяется срез. Срез позволяет выбрать диапазон символов по индексам. Синтаксис выглядит так: строка[начало:конец:шаг], где начало — индекс первого символа, который включается, конец — индекс символа, до которого идёт выборка (не включая его), а шаг — шаг перемещения по строке. Например, text[1:5] извлечёт символы с индексами 1, 2, 3, 4. Если шаг указать как 2: text[0:6:2], будут выбраны символы через один.