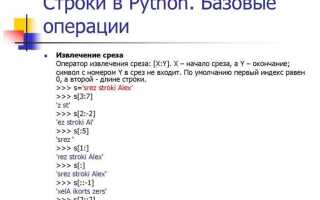
В Python работа со строками предоставляет гибкие инструменты для извлечения их фрагментов. Основной способ – использование срезов (slicing), где синтаксис string[start:stop:step] позволяет получить любой участок строки, включая каждый n-й символ или диапазон с отрицательными индексами для обращения с конца.
Метод split() подходит для разделения строки по разделителю и последующего извлечения нужного элемента. Например, data.split(‘,’)[2] вернёт третий элемент списка после разбиения строки по запятой. Этот метод удобен при работе с CSV или логами.
Регулярные выражения через модуль re дают возможность извлекать подстроки по шаблону. Использование re.search() или re.findall() особенно эффективно для сложных текстов с переменными форматами, где простые срезы и split() не подходят.
Методы find() и index() помогают определить позиции подстрок, чтобы затем извлечь сегмент с помощью срезов. Такой подход полезен, когда нужно достать часть строки между двумя конкретными символами или словами без полного разбиения на элементы.
Извлечение части строки в Python: примеры и способы
В Python извлечение подстрок выполняется с помощью срезов, методов строк и регулярных выражений. Рассмотрим ключевые способы и их особенности.
1. Использование срезов (slicing)

Срезы позволяют получить часть строки по индексам. Формат: string[start:end:step].
string[2:7]– символы с индекса 2 до 6 включительно.string[:5]– первые пять символов.string[3:]– все символы с индекса 3 до конца.string[::2]– каждый второй символ всей строки.string[-5:-1]– срез с конца, с индекса -5 до -2.
2. Методы строк
Некоторые встроенные методы позволяют извлекать части строки по содержимому.
split()– делит строку по разделителю и возвращает список. Например,"a,b,c".split(",")→['a','b','c'].partition()– разделяет строку на три части по первому вхождению разделителя: до, сам разделитель, после."user@example.com".partition("@")→('user','@','example.com').find()– возвращает индекс первого вхождения подстроки, что позволяет использовать его для среза.string[:string.find(" ")]извлекает первую часть до пробела.
3. Регулярные выражения
Регулярные выражения подходят для извлечения подстрок по сложным шаблонам.
- Используется модуль
re:import re. re.search(pattern, string).group()– извлекает первую подстроку, совпадающую с шаблоном.re.findall(pattern, string)– возвращает список всех совпадений. Пример:re.findall(r'\d+', "abc123def45")→['123','45'].
4. Срезы с отрицательными шагами
С помощью отрицательного шага строки можно переворачивать и извлекать части в обратном порядке.
string[::-1]– полностью переворачивает строку.string[5:0:-1]– символы с индекса 5 до 1 в обратном порядке.
5. Комбинирование методов и срезов
Для сложных случаев можно сочетать методы и срезы. Примеры:
string.split()[1][:3]– второй элемент после разбиения и первые три символа этого элемента.string.partition("-")[2][-4:]– часть после разделителя, последние четыре символа.
Выбор метода зависит от структуры строки и задачи: для фиксированных позиций оптимальны срезы, для разделителей – split и partition, для шаблонов – регулярные выражения.
Использование срезов для получения подстроки по индексам

Срезы в Python позволяют извлекать подстроки по конкретным индексам с помощью синтаксиса строка[начало:конец]. Значение начало указывает индекс первого символа включительно, конец – индекс символа, на котором извлечение прекращается, исключая его.
Пример: text = "Python", text[1:4] вернёт 'yth'. Символ с индексом 1 включён, с индексом 4 – исключён.
Если пропустить начало, срез начнётся с первого символа: text[:3] даст 'Pyt'. Пропуск конца возвращает все символы до конца строки: text[2:] вернёт 'thon'.
С отрицательными индексами можно извлекать подстроки с конца строки. text[-4:-1] вернёт 'tho', где -1 соответствует последнему символу.
Шаг среза задаётся третьим параметром: text[::2] извлечёт каждый второй символ, результат 'Pto'. Можно использовать отрицательный шаг для обращения строки: text[::-1] даст 'nohtyP'.
Для больших строк рекомендуется сохранять срезы в переменные вместо многократного вызова, это повышает читаемость и снижает вероятность ошибок при работе с индексами.
Извлечение первых и последних символов строки

Для получения первого символа строки в Python используется индекс 0: string[0]. Например, text = «Python»; text[0] вернёт ‘P’. Если требуется несколько первых символов, применяется срез: text[:n], где n – количество символов. Пример: text[:3] даст ‘Pyt’.
Последний символ извлекается через отрицательный индекс -1: text[-1]. Для нескольких последних символов используется срез с отрицательным индексом: text[-n:] . Например, text[-2:] вернёт ‘on’.
Комбинация срезов позволяет получать и первые, и последние символы одновременно: text[:2] + text[-2:] создаст строку из первых двух и последних двух символов исходной строки.
При использовании срезов важно учитывать длину строки. Если n больше длины строки, Python вернёт всю строку без ошибки.
Для динамического выбора символов можно использовать переменные: start = 1; end = 3; text[start:end] извлечёт подстроку с индекса 1 по 2 включительно. Аналогично для последних символов: text[-end:].
Получение подстроки по условию содержимого
В Python извлечение подстроки на основе её содержимого удобно выполнять с помощью методов строк и регулярных выражений. Если необходимо получить часть строки, содержащую определённое слово или символ, используют метод find() для определения позиции и срезы:
text = "Ошибка: файл не найден"
pos = text.find("файл")
if pos != -1:
result = text[pos:pos+4]
Для поиска всех вхождений подстрок подходит метод re.findall(). Он позволяет задавать сложные шаблоны и возвращает список совпадений:
import re
text = "ID:123, ID:456, ID:789"
matches = re.findall(r"ID:\d+", text)
# matches = ['ID:123', 'ID:456', 'ID:789']
Иногда требуется извлечь подстроку между двумя ключевыми словами. Используют split() для разбиения строки:
text = "Пользователь: Иван, возраст: 30"
name = text.split("Пользователь: ")[1].split(",")[0]
# name = 'Иван'
Для проверки наличия части строки перед извлечением применяют in:
if "ошибка" in text.lower():
error_msg = text[text.lower().find("ошибка"): ]
При динамическом содержимом удобно использовать списковые включения для фильтрации и извлечения подстрок из списка строк:
lines = ["OK: 200", "Ошибка: 404", "OK: 201"]
errors = [line for line in lines if "Ошибка" in line]
# errors = ['Ошибка: 404']
Методы find(), split(), re.findall() и проверка через in позволяют гибко получать подстроку по условию, не создавая лишних операций и сохраняя производительность. Их комбинирование облегчает извлечение данных из строк с переменной структурой.
Работа с методом split для разбиения строки
Метод split() разделяет строку на части по указанному разделителю и возвращает список. Если разделитель не указан, по умолчанию используется пробел. Пример: ‘яблоко,банан,вишня’.split(‘,’) вернёт [‘яблоко’, ‘банан’, ‘вишня’].
Метод принимает необязательный аргумент maxsplit, который ограничивает количество разбиений. Например, ‘a-b-c-d’.split(‘-‘, 2) вернёт [‘a’, ‘b’, ‘c-d’], где разбиение произошло только дважды.
Чтобы удалить лишние пробелы, можно сочетать split() с strip(): [x.strip() for x in ‘ один , два , три ‘.split(‘,’)] даст [‘один’, ‘два’, ‘три’].
Метод split() подходит для разбора строк с разными разделителями. Для нескольких символов-разделителей используют регулярные выражения через re.split(). Например, re.split(‘[,;]’, ‘a,b;c’) вернёт [‘a’, ‘b’, ‘c’].
При работе с CSV или логами важно учитывать пустые элементы: ‘a,,b’.split(‘,’) вернёт [‘a’, », ‘b’]. Для игнорирования пустых строк используют генераторы: [x for x in s.split(‘,’) if x].
Метод split() эффективно обрабатывает большие строки и позволяет извлекать нужные фрагменты без сложных циклов, что ускоряет работу с текстовыми данными и упрощает последующую обработку.
Применение метода find для поиска и извлечения части строки

Метод find возвращает индекс первого вхождения подстроки в строке. Если подстрока не найдена, метод возвращает -1. Для извлечения части строки сначала определяют позицию начала подстроки, затем применяют срез.
Пример: извлечение слова между двумя известными маркерами:
text = "Дата: 2025-09-12, Время: 14:30"
start = text.find("Дата: ") + len("Дата: ")
end = text.find(", Время")
date = text[start:end]
Здесь start указывает на первый символ даты, end – на начало следующей подстроки. Результат date будет '2025-09-12'.
Для поиска нескольких вхождений используют цикл с указанием начальной позиции в методе find(sub, start). Это позволяет последовательно извлекать все совпадения.
Пример поиска всех слов «Ошибка» в строке:
text = "Ошибка 1. Ошибка 2. Ошибка 3."
pos = 0
while True:
pos = text.find("Ошибка", pos)
if pos == -1: break
print(pos)
pos += 1
Использование find в комбинации с срезами позволяет извлекать подстроки, не прибегая к регулярным выражениям, и точно контролировать диапазон символов.
Если необходимо извлечь часть строки до конца после найденного маркера, достаточно указать только начальный индекс в срезе: substring = text[start:]. Такой подход эффективен при фиксированных префиксах или метках.
Извлечение подстроки с помощью регулярных выражений
Регулярные выражения в Python реализованы через модуль re. Они позволяют искать и извлекать части строки по заданным шаблонам.
Основные функции для извлечения подстрок:
re.search(pattern, string)– ищет первое совпадение. Возвращает объектMatch, из которого можно получить подстроку черезgroup().re.findall(pattern, string)– возвращает список всех непересекающихся совпадений.re.finditer(pattern, string)– возвращает итератор объектовMatchдля последовательной обработки совпадений.
Примеры шаблонов:
r'\d{4}'– последовательность из 4 цифр.r'[A-Za-z]+'– последовательность латинских букв.r'(\w+)@(\w+\.\w+)'– извлечение адреса электронной почты с разделением на имя и домен.
Пример использования re.search:
import re
text = "Дата публикации: 2025-09-12"
match = re.search(r'\d{4}-\d{2}-\d{2}', text)
if match:
print(match.group()) # 2025-09-12
Пример извлечения нескольких совпадений с помощью re.findall:
import re
text = "Контакты: user1@mail.com, user2@mail.com"
emails = re.findall(r'\w+@\w+.\w+', text)
print(emails) # ['user1@mail.com', 'user2@mail.com']
Использование групп позволяет получать конкретные части подстроки:
import re
text = "Email: user@mail.com"
match = re.search(r'(\w+)@(\w+.\w+)', text)
if match:
print(match.group(1)) # user
print(match.group(2)) # mail.com
Для регулярных выражений рекомендуется:
- Использовать
r''для сырых строк, чтобы экранировать символы не вручную. - Проверять шаблон через онлайн-тестировщики.
- Использовать именованные группы
(?P<имя>...)для читаемости сложных выражений.
Использование метода partition для отделения нужной части
Метод partition() разделяет строку на три части: до указанного разделителя, сам разделитель и после него. Возвращает кортеж из трёх элементов. Этот метод эффективен, когда необходимо получить конкретную часть строки без использования сложных срезов или регулярных выражений.
Синтаксис:
string.partition(sep)
Пример:
Допустим, есть строка с адресом электронной почты:
email = "user@example.com"
Чтобы отделить имя пользователя и домен:
username, sep, domain = email.partition("@")
Результат:
| username | sep | domain |
|---|---|---|
| user | @ | example.com |
Метод удобен для извлечения первых сегментов строки:
text = "2025-09-12_report.txt"
date, sep, filename = text.partition("_")
| date | sep | filename |
|---|---|---|
| 2025-09-12 | _ | report.txt |
Если разделитель отсутствует, partition() возвращает исходную строку как первый элемент, а два других – пустые:
result = "datafile".partition("_")
| Первый | Второй | Третий |
|---|---|---|
| datafile |
Рекомендации:
- Используйте, когда разделитель встречается один раз, либо требуется только первый сегмент.
- Для всех вхождений разделителя лучше использовать
split(). - Метод возвращает кортеж, что облегчает распаковку в переменные.
Получение символов с шагом с помощью срезов

В Python срезы позволяют не только выделять диапазон символов, но и задавать шаг, что упрощает выборку через один или несколько элементов. Синтаксис среза с шагом: строка[начало:конец:шаг]. Если шаг положительный, извлечение идёт слева направо, отрицательный – справа налево.
Пример извлечения каждого второго символа:
text = "abcdefgh"
result = text[::2]
Для обратного порядка используется отрицательный шаг:
result = text[::-1]
Шаг позволяет комбинировать с диапазоном. Например, взять каждый третий символ с позиции 1 до 7:
result = text[1:7:3]
Если указать только шаг, без начала и конца, Python автоматически использует начало строки как старт и конец как ограничение. Для отрицательного шага начало и конец меняются местами: text[::-2] вернёт каждый второй символ в обратном порядке.
Шаг 1 является значением по умолчанию и может опускаться. Изменение шага позволяет быстро формировать выборки с регулярной периодичностью без использования циклов.
При работе с большими строками использование срезов с шагом экономит память и ускоряет выполнение, так как создаётся новый объект строки только с нужными символами, без промежуточных копий.
Вопрос-ответ:
Как в Python получить часть строки по индексам?
Для извлечения части строки по индексам используется синтаксис срезов: `строка[начало:конец]`. Параметр `начало` указывает позицию первого символа, который будет включён, а `конец` — позицию символа, на котором срез заканчивается (сам символ с этим индексом не включается). Например, `text = «Python»` и `text[1:4]` вернёт `»yth»`. Если `начало` или `конец` опущены, Python автоматически использует начало или конец строки соответственно.
Можно ли извлечь часть строки с шагом символов?
Да, Python позволяет указывать шаг через третий параметр в срезе: `строка[начало:конец:шаг]`. Например, `text = «abcdef»` и `text[0:6:2]` вернёт `»ace»`, поскольку шаг равен 2, и берутся символы через один. Если шаг отрицательный, строка возвращается в обратном порядке, что позволяет легко переворачивать подстроки.
Как получить подстроку с конца строки?
Python поддерживает отрицательные индексы, которые отсчитываются с конца строки: `-1` — последний символ, `-2` — предпоследний и так далее. Например, `text = «Python»` и `text[-3:-1]` вернёт `»ho»`. Это удобно, когда точное количество символов с конца известно, а длина всей строки может быть разной.
Есть ли стандартные функции для выделения подстроки по содержимому?
Да, можно использовать методы `find()` или `index()` для поиска позиции символа или подстроки, а затем применять срез. Например, `text = «Hello, Python»`; чтобы получить слово `»Python»`, сначала находим индекс начала: `start = text.find(«Python»)`, затем делаем срез: `text[start:start+6]`. Методы `split()` или `partition()` тоже помогают извлечь часть строки на основе разделителей.