Процесс передачи больших объёмов данных из 1С в Битрикс требует особого подхода к структуре и формату информации. Highload-сущности в Битрикс предназначены для хранения миллионов записей, поэтому стандартные методы обмена через REST API или COM-соединение могут стать узким местом при объёмах свыше 500 тысяч строк.
Для оптимизации выгрузки рекомендуется использовать пакетную передачу данных с делением на блоки по 5–10 тысяч записей. Это позволяет уменьшить нагрузку на сервер 1С и предотвратить превышение лимитов API Битрикс. Формат обмена – JSON или CSV с обязательной валидацией типов данных перед импортом.
Важный момент – индексирование полей highload-блоков перед загрузкой. Создание индексов по ключевым атрибутам ускоряет обработку запросов и позволяет избежать ошибок при массовом обновлении записей. Для больших каталогов товаров или клиентской базы использование индексов снижает время обработки выгрузки в 2–3 раза.
Для регулярных обновлений данных целесообразно настроить инкрементальную выгрузку. Сравнивая timestamp изменений в 1С с последним обновлением в Битрикс, можно передавать только новые или изменённые записи, что уменьшает нагрузку и ускоряет синхронизацию.
Контроль ошибок должен быть встроен на уровне 1С и Битрикс. Логирование неудачных операций, повторная обработка блоков с ошибками и уведомления администратора позволяют поддерживать целостность базы данных и избегать потерь информации при массовых обновлениях.
Настройка подключения 1С к внешнему API Битрикс
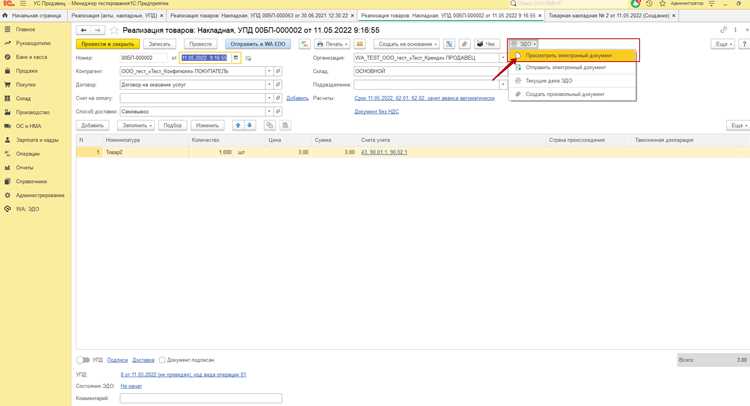
Для подключения 1С к внешнему API Битрикс необходимо использовать механизм HTTP-запросов в 1С. В конфигураторе создается внешняя обработка, которая использует объекты «HTTPСоединение» и «HTTPЗапрос».
Адрес API формируется по шаблону: https://yourdomain.bitrix24.ru/rest/{USER_ID}/{WEBHOOK_KEY}/. Для операций выгрузки highload данных рекомендуется использовать метод crm.deal.list или аналогичный метод HL-блока с фильтрацией по дате изменения.
Аутентификация осуществляется через вебхук. В 1С в объекте «HTTPЗапрос» устанавливается заголовок Content-Type: application/json и тело запроса формируется в формате JSON с указанием нужных фильтров и полей. Для больших объемов данных применяют постраничную выборку через параметр start, чтобы избежать тайм-аутов.
При обработке ответов важно использовать метод «ПрочитатьТелоКакСтроку()» и функцию JSONПрочитать для конвертации ответа в структуру 1С. Ошибки API фиксируются через свойство КодСостояния HTTP-ответа и тело ответа для анализа ошибок.
Рекомендуется сохранять контрольные точки выгрузки: дату последнего обновления и идентификатор последней обработанной записи. Это позволяет возобновлять процесс без повторной обработки всех данных.
Для автоматизации создается регламентное задание в 1С с периодичностью, соответствующей нагрузке и времени обновления данных. В случае highload объектов лучше использовать пакетную обработку: делить выборку на блоки по 500–1000 записей, чтобы уменьшить нагрузку на сервер и избежать разрыва соединения.
Важный момент – логирование запросов и ответов. Рекомендуется записывать URL, параметры и код состояния HTTP, а также количество обработанных записей. Это облегчает отладку и мониторинг стабильности интеграции.
Формирование выборки highload-данных для выгрузки
Для эффективной выгрузки highload-данных из 1С в Битрикс критически важно точно определить набор записей и минимизировать нагрузку на систему. Процесс начинается с анализа структуры справочников и регистров, участвующих в выгрузке.
Рекомендации по формированию выборки:
- Определите ключевые поля для фильтрации: идентификаторы, даты изменения, статусы.
- Используйте диапазоны дат изменения для постепенной выгрузки, чтобы исключить повторное извлечение одних и тех же записей.
- Фильтруйте по признаку активности записи (например, поле «ПометкаУдаления» = «0»), чтобы выгружать только актуальные данные.
- Составьте отдельные выборки для разных типов данных: справочники, документы, регистры накопления, чтобы оптимизировать обработку и синхронизацию.
- При большом объеме данных используйте разбивку на блоки по 500–5000 записей, чтобы избежать таймаутов при выгрузке.
- Применяйте индексы 1С при выборке по часто фильтруемым полям, чтобы ускорить обработку.
- Проверяйте соответствие типов данных в 1С и Битрикс, особенно для числовых и строковых полей, чтобы избежать ошибок при импорте.
- Для сложных выборок используйте запросы через механизм «Запрос» в 1С с конкретным набором полей, вместо полного чтения объектов.
Формирование выборки по этим принципам позволяет уменьшить нагрузку на базу 1С и ускоряет последующую обработку в Битрикс. Планирование выборок с учетом объема и структуры данных снижает вероятность сбоев и потери данных при автоматической выгрузке.
Оптимизация пакетной передачи больших объемов данных
При выгрузке highload данных из 1С в Битрикс критично контролировать размер пакетов. Рекомендуется разбивать данные на блоки по 500–1000 записей, чтобы избежать таймаутов и перегрузки сервера. Для объектов с большим числом полей оптимальный размер пакета может уменьшаться до 200–300 записей.
Используйте прямую выгрузку через COM-соединение или веб-сервисы 1С с передачей JSON, минимизируя промежуточные форматы. Сериализация данных в JSON позволяет уменьшить размер передаваемых пакетов на 15–25% по сравнению с XML.
Для ускорения обработки в Битриксе применяйте bulk-операции через API: метод `crm.entity.addBatch` для CRM или `iblock.element.addBatch` для инфоблоков. Это сокращает количество HTTP-запросов, снижая нагрузку на сеть и ускоряя вставку данных в 3–5 раз.
Организуйте параллельную обработку нескольких пакетов с использованием очередей: RabbitMQ, Redis или встроенных механизмов Битрикс. Оптимальное количество потоков – 3–5, чтобы не превышать лимиты сервера и базы данных.
Для больших таблиц 1С включайте фильтрацию и выборку только измененных записей за последние N дней. Использование индексов и фильтров на стороне 1С снижает объем передаваемых данных на 40–60%, сокращая время выгрузки.
Контролируйте логирование: фиксируйте только критические ошибки, избегая записи всех обработанных строк. Это уменьшает нагрузку на файловую систему и ускоряет работу скриптов.
Регулярно тестируйте нагрузку: сравнивайте время передачи пакета 500, 1000 и 2000 записей. В большинстве случаев стабильная работа достигается на 800–1000 элементах для стандартных серверов с 8–16 ГБ оперативной памяти.
Обработка ошибок при передаче данных в Битрикс
При выгрузке highload данных из 1С в Битрикс важно предусмотреть механизм фиксации и анализа ошибок. Без него пропуски и дублирование данных становятся неизбежными.
Рекомендуется реализовать следующие шаги:
- Использовать отдельный лог-файл для каждой выгрузки. Лог должен содержать: дату и время попытки передачи, идентификатор записи 1С, результат операции, текст ошибки.
- Разделять ошибки по типу: сетевые, ограничения Битрикс (например, уникальные поля), ошибки формата данных, таймауты.
- Применять повторные попытки передачи для сетевых и временных ошибок с экспоненциальной задержкой.
- Валидация данных перед отправкой: проверка длины строк, числовых форматов, обязательных полей. Это снижает количество ошибок на стороне Битрикс.
Для интеграции можно использовать следующий подход:
- Передача данных через REST API Битрикс с проверкой кода ответа: 200 – успешно, 4xx/5xx – ошибка. Код ошибки сохраняется в логе.
- В случае ошибки сохранять запись в отдельную таблицу retry, включая все поля, необходимые для повторной передачи.
- Автоматическая обработка повторных попыток через cron с ограничением числа итераций на одну запись.
- Использование JSON-валидатора при формировании payload для исключения синтаксических ошибок.
Дополнительно рекомендуется:
- Настроить уведомления на критические ошибки (например, превышение лимита запросов или ошибки уникальных ключей) через email или Telegram-бота.
- Сохранять статистику успешных и неуспешных попыток для последующего анализа производительности выгрузки.
- Разделять большие пакеты данных на блоки по 500–1000 записей, чтобы ошибки не блокировали весь процесс передачи.
Эта схема позволяет минимизировать потерю данных и ускоряет выявление проблем при синхронизации 1С и Битрикс.
Автоматизация выгрузки по расписанию с помощью 1С
Для автоматизации выгрузки данных из 1С в Битрикс используется планировщик заданий 1С. В конфигурациях на платформе 1С:Предприятие 8.3 создается регламентное задание, которое запускает обработку выгрузки по расписанию.
В обработке необходимо настроить последовательность действий: формирование выборки данных, преобразование структуры в формат XML или JSON и отправка через REST API Битрикс. Для highload таблиц рекомендуется использовать пакетную обработку по 1000–5000 записей за один цикл, чтобы снизить нагрузку на сервер и избежать таймаутов.
Регламентное задание настраивается через «Администрирование → Регламентные задания». В параметрах указывается периодичность запуска (например, каждые 30 минут или раз в час), а также время ожидания повторных попыток при ошибках соединения. Важно включить логирование: записывать количество выгруженных записей, ошибки соединения и время выполнения каждой итерации.
Для обеспечения непрерывной работы рекомендуется использовать отдельного пользователя с минимальными правами, необходимыми для чтения данных и отправки через API. Это предотвращает блокировку основной учетной записи при массовых операциях.
Для контроля корректности выгрузки можно настроить уведомления по электронной почте или через внутренние события 1С, которые информируют о завершении процесса и о наличии ошибок. В случае highload выгрузок полезно тестировать обработку на выборке из 10–20 тысяч записей, чтобы оценить время выполнения и распределение нагрузки.
При использовании REST API Битрикс следует применять методы пакетной обработки данных: отправка до 500 записей за один запрос ускоряет процесс и снижает вероятность ошибок сервера. Для больших объемов данных лучше реализовать механизм «постраничной» выгрузки с контролем статуса обработки каждой страницы.
Регулярное обновление конфигурации 1С и библиотеки интеграции с Битрикс обеспечивает совместимость с изменениями API и предотвращает сбои автоматизированной выгрузки. Рекомендуется вести версионный контроль обработок и регламентных заданий для быстрого восстановления при сбоях.
Сравнение методов вставки данных в highload-блоки Битрикс
В Битрикс существуют три основных способа добавления данных в highload-блоки: через API Bitrix (`\Bitrix\Highloadblock\HighloadBlockTable` и `\Bitrix\Highloadblock\HighloadBlockTable::compileEntity`), через ORM и через массовую вставку SQL
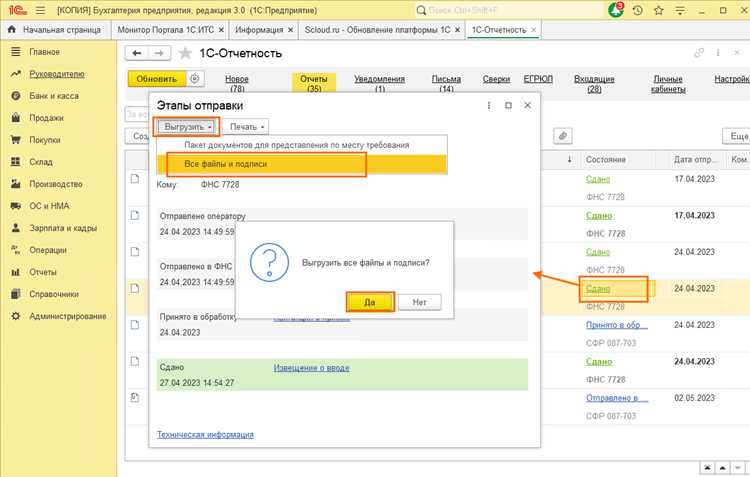
API Bitrix позволяет безопасно создавать записи и автоматически обрабатывать типы полей, но на больших объемах данных (свыше 100 000 записей) скорость снижается до 10–50 записей в секунду. Метод требует загрузки сущности и вызова метода `add()` для каждой записи, что создаёт дополнительную нагрузку на ядро. ORM подходит для работы с объектами в коде и обеспечивает проверку типов, но массовые вставки через цикл `add()` практически не выигрывают в производительности по сравнению с прямым API. Преимущество ORM – возможность использовать встроенные фильтры и связи с другими highload-блоками. Массовая вставка через SQL демонстрирует максимальную скорость – до тысяч записей в секунду. Используются прямые `INSERT` в таблицу базы данных highload-блока. Недостаток – необходимость самостоятельно управлять экранированием данных и соответствием типов. Рекомендуется для сценариев, когда данные предварительно обработаны и проверены, например при выгрузке из 1С. Для оптимизации импорта рекомендуется комбинировать методы: проверка и обработка данных через API или ORM, а затем пакетная вставка через SQL. Также важно использовать транзакции при массовой вставке, чтобы исключить частичное добавление при сбоях. При регулярной синхронизации с 1С для highload-блоков с более чем 500 000 записей лучше формировать временные таблицы, затем вставлять блоками по 10 000–50 000 записей с помощью SQL. Это минимизирует блокировки и нагрузку на сервер. При выгрузке highload данных из 1С в Битрикс критически важно фиксировать каждый этап передачи. Логирование должно включать отметку времени, идентификатор записи, статус обработки и ошибки, если они возникли. Рекомендуется использовать отдельный лог-файл для каждой сессии выгрузки. Формат записи может быть следующим: Для контроля успешной передачи данных необходимо внедрить механизм сверки. После каждой выгрузки 1С формирует CSV с переданными ID, который автоматически сравнивается с таблицей в Битрикс. Разница фиксируется и сразу передается ответственному специалисту. Также полезно настроить автоматические уведомления. Например, если количество ошибок превышает 1% от объема выгрузки, система отправляет письмо с логом ошибок и ссылкой на проблемные записи. При регулярной выгрузке рекомендуется хранить логи минимум 30 дней для аудита и анализа трендов по ошибкам. Это позволяет выявлять повторяющиеся проблемы, например, некорректные значения реквизитов или несоответствия форматов. Существует несколько подходов: через прямое подключение к базе данных 1С с использованием SQL-запросов, через веб-сервисы 1С, а также через обмен по XML или JSON. Выбор зависит от объёма данных и требований к скорости передачи. Для highload объектов чаще используют веб-сервисы или API Битрикс, чтобы избежать блокировок и перегрузки серверов. Для снижения нагрузки данные выгружают частями, используя пагинацию или пакетную обработку. В 1С можно настроить обработку запросов блоками по несколько тысяч записей. На стороне Битрикс рекомендуется использовать массовые методы добавления или обновления элементов инфоблоков через API, чтобы не вызывать многократные отдельные обращения к базе. Возможны оба варианта. Для реального времени используется прямое соединение через веб-сервисы, когда изменения из 1С передаются сразу. Для регулярной синхронизации часто применяют cron-задачи или планировщик заданий 1С, чтобы выгрузка происходила по расписанию, например, каждые 15 минут или один раз в час. Выбор зависит от частоты обновления данных и возможностей серверов. Чаще всего возникают ошибки из-за превышения лимитов памяти или времени выполнения скриптов, некорректного формата данных, несоответствия типов полей между 1С и Битрикс. Также возможны конфликты при параллельной записи в базу, когда несколько процессов одновременно обновляют одни и те же элементы. Чтобы избежать проблем, используют пакетную обработку и проверку типов данных перед загрузкой. На стороне 1С можно вести журнал выполнения обработки, записывая количество выгруженных записей и возникающие ошибки. В Битрикс рекомендуется сохранять логи выполнения API-запросов с указанием времени, статуса выполнения и идентификаторов элементов. Логирование помогает выявить сбои, определить проблемные участки и повторно обработать только неудачные блоки данных.Логирование и контроль успешной передачи данных
Время
ID записи
Статус
Описание ошибки
2025-09-03 10:15:23
4521
Успешно
—
2025-09-03 10:15:25
4522
Ошибка
Невалидный формат даты
Вопрос-ответ:
Какие существуют методы выгрузки больших объёмов данных из 1С в Битрикс?
Как уменьшить нагрузку на сервер при выгрузке больших массивов данных?
Можно ли выгружать данные в реальном времени или только по расписанию?
Какие ошибки чаще всего встречаются при выгрузке highload данных?
Как отслеживать и логировать процесс выгрузки данных?